
Pakiet rust dla libmdbx
Narzędzie rust do obsługi bazy danych libmdbx.
Spis treści :
Cytaty
Podczas pisania programu "rmw.link " poczułem, że potrzebuję wbudowanej bazy danych.
Ze względu na przepustowość sieci związaną z częstym zapisywaniem, odczytywaniem i zapisywaniem danych, strona sqlite3 była zbyt zaawansowana, aby sprostać wymaganiom dotyczącym wydajności.
Dlatego bardziej odpowiednia była baza danych klucz-wartość niższego poziomu (lmdb jest 10 razy szybsza niż sqlite ).

Ostatecznie zdecydowałem się na magiczną wersję strony lmdb - mdbx.
mdbx Obecnie istniejący pakiet mdbx-rs (mdbx-sys) ze strony rust nie obsługuje systemu Windows, więc postanowiłem przygotować wersję z obsługą systemu Windows.
Obsługa przechowywania niestandardowych typów rdzy. Obsługuje dostęp wielowątkowy.
Bazę danych można zdefiniować w module za pomocą lazy_static, a następnie po prostu wprowadzić i używać jej za pomocą czegoś w rodzaju :
use db::User;
let id = 1234;
let user = r!(User.get id);
Co to jest libmdbx?
mdbx jest wtórną bazą danych opartą na lmdb, autorstwa rosyjskiego Леонид Юрьев (Leonid Yuriev).
lmdb to superszybka wbudowana baza danych klucz-wartość.
Wyszukiwarka pełnotekstowa MeiliSearch jest oparta na lmdb.
Framework do głębokiego uczenia caffe również używa lmdb jako magazynu danych.
W teście wydajności wbudowanej ioarena mdbx jest o 30% szybszy niż lmdb.
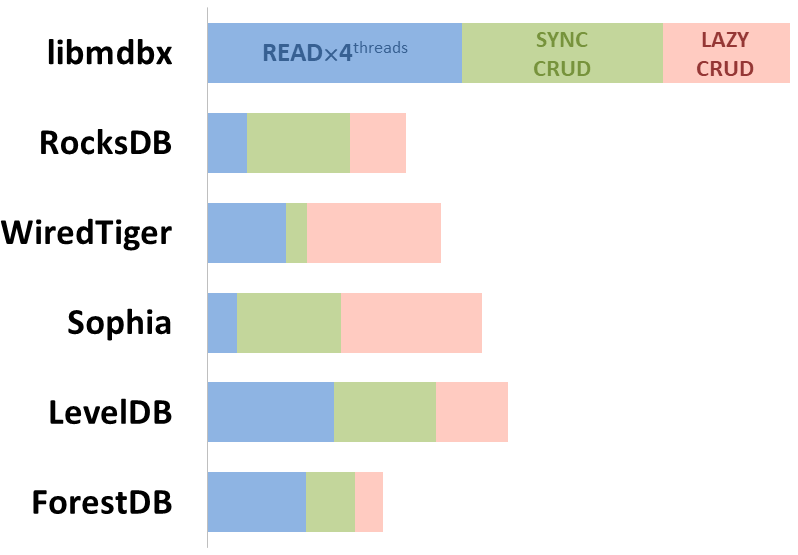
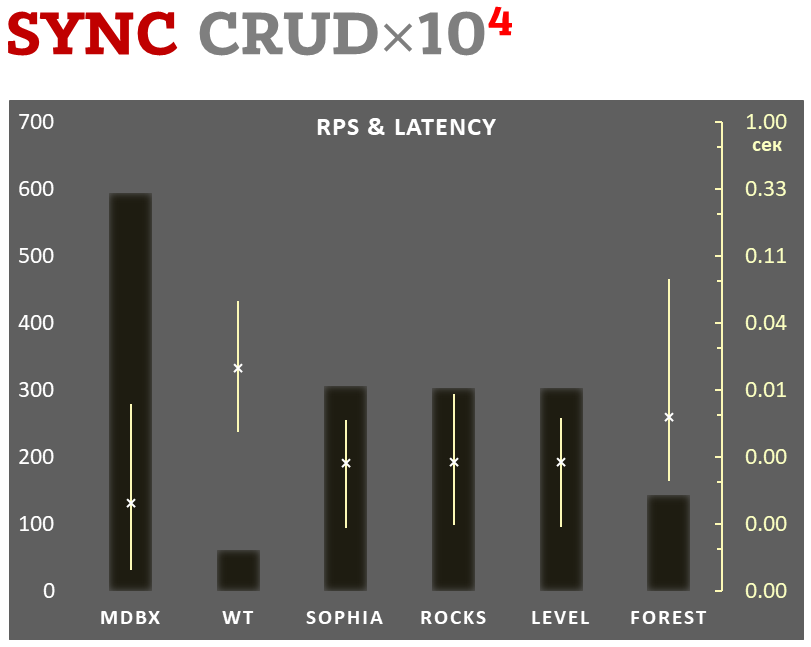
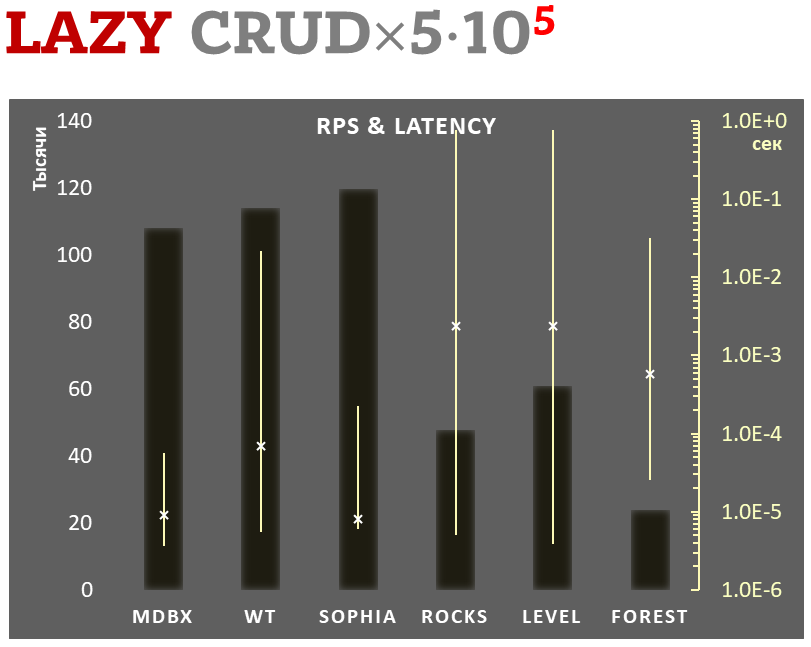
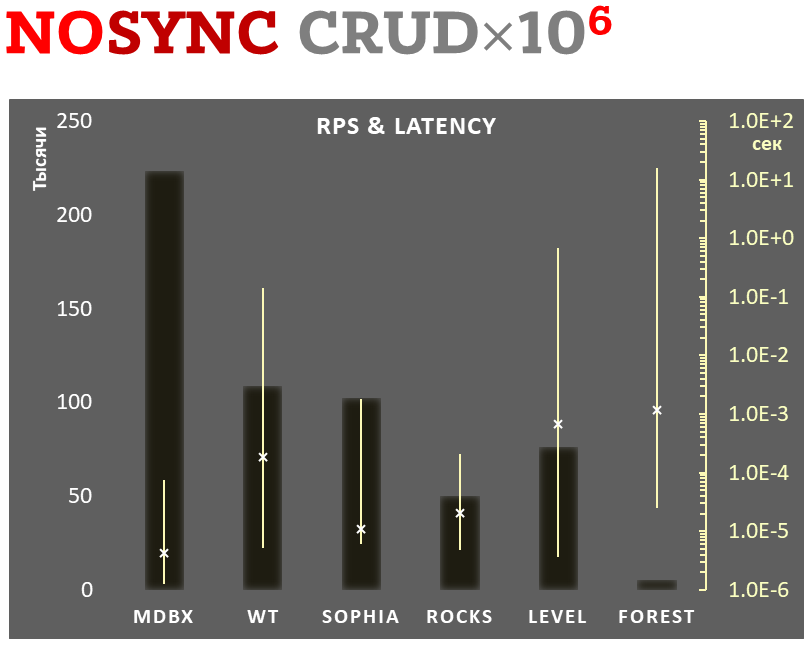
Jednocześnie mdbx poprawia wiele niedociągnięć lmdb, dlatego Erigon (klient ethereum nowej generacji) niedawno przeszedł z LMDB na MDBX [1].
Samouczki
Jak uruchomić przykład
Najpierw należy sklonować bazę kodów git clone git@github.com:rmw-lib/mdbx.git --depth=1 && cd mdbx
Następnie należy uruchomić stronę cargo run --example 01, co spowoduje uruchomienie examples/01.rs
Jeśli jest to własny projekt, należy go najpierw uruchomić:
cargo install cargo-edit
cargo add mdbx lazy_static ctor paste
Przykład 1: Pisanie set(key,val) i czytanie .get(key)
Przyjrzyjmy się prostemu przykładowi/01.rs
Kod
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
Uruchom wyjście
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/01.mdb
mdbx version https://github.com/erthink/libmdbx/releases/tag/v0.11.2
test1 get Ok(Some(Bin([6])))
[6]
Opis kodu
env_rw! Definiowanie bazy danych
Kod rozpoczyna się od makra env_rw, które ma 4 parametry.
Nazwa zmiennej środowiska bazy danych
Zwraca obiekt, mdbx:: env:: Config.
Używamy konfiguracji domyślnej, ponieważ Env implementuje From<Into<PathBuf>>, więc wystarczy ścieżka do bazy danych into(), a konfiguracja domyślna jest następująca.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
max_db Ustawienie to może być resetowane przy każdym otwarciu bazy danych, ale zbyt duże jego ustawienie może wpłynąć na wydajność.
Znaczenie pozostałych parametrów można znaleźć w dokumentacji libmdbx.
Nazwa makra transakcji odczytu bazy danych, wartość domyślna to
rNazwa makra transakcji zapisu do bazy danych, wartość domyślna to
w
Parametry 3 i 4 można pominąć, aby zastosować wartości domyślne.
Makroekspansja
Jeśli chcesz zobaczyć, co robi magia makr, możesz użyć makra cargo expand --example 01, które trzeba najpierw zainstalować, aby je rozwinąć. cargo install cargo-expand
Poniżej pokazano zrzut ekranu z rozszerzonym kodem.

w każdym razie i lazy_static
Na rozwiniętym zrzucie ekranu widać, że używane są adresy lazy_static i anyhow.
anyhow jest biblioteką obsługi błędów dla języka rust.
lazy_static to zmienna statyczna z opóźnioną inicjalizacją.
Te dwie biblioteki są bardzo powszechne i nie będę się nad nimi rozwodzić.
Makro mdbx!
mdbx! jest makrem proceduralnym.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
W pierwszym wierszu podajemy nazwę zmiennej środowiska bazy danych
W drugim wierszu znajduje się nazwa bazy danych
Może istnieć więcej niż jedna baza danych, po jednym wierszu dla każdej z nich.
Wątki i transakcje
Powyższy kod demonstruje wielowątkowy odczyt i zapis.
Należy pamiętać, że w danym momencie w tym samym wątku może znajdować się tylko jedna transakcja. Jeśli w wątku otwartych jest więcej niż jedna transakcja, program ulegnie awarii.
Transakcja zostanie zrealizowana po zakończeniu zakresu.
Odczyt i zapis danych binarnych
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
set jest zapisem, get jest odczytem, a każdy obiekt, który implementuje AsRef<[u8]> może zostać zapisany w bazie danych.
get Powstaje strona Ok(Some(Bin([6]))), którą można przekształcić na &[u8].
Przykład 2: Typy danych, flagi bazy danych, usuwanie, przeglądanie
Przyjrzyjmy się drugiemu przykładowi/02.rs:
W tym przykładzie pominięto stronę env_rw! oraz trzeci i czwarty argument ( r, w).
Kod
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
Uruchom wyjście
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/02.mdb
u16::from_le_bytes(Bin([4, 5])) = 1284
-- loop test1
[2] = [3]
[2, 3] = [4, 5]
[8, 1] = [9]
[9] = [10, 12]
[97, 98, 99] = [48, 49, 50]
[114, 109, 119, 46, 108, 105, 110, 107] = [68, 111, 119, 110, 32, 119, 105, 116, 104, 32, 68, 97, 116, 97, 32, 72, 101, 103, 101, 109, 111, 110, 121]
[examples/02.rs:57] test1.del_val([8, 1], [3])? = false
[examples/02.rs:58] test1.get([8, 1])?.unwrap() = Bin(
[
9,
],
)
[examples/02.rs:59] test1.del_val([8, 1], [9])? = true
[examples/02.rs:60] test1.get([8, 1])? = None
[examples/02.rs:62] test1.del([9])? = true
[examples/02.rs:63] test1.get([9])? = None
[examples/02.rs:64] test1.del([9])? = false
-- loop test2
abc = 012
rmw.link = Down with Data Hegemony
-- loop test3
0 = 6
10 = 5
13 = 32
16 = 32
-15 = 6
-12 = 6
-10 = 6
[examples/02.rs:100] test4.del_val(0, 2)? = true
[examples/02.rs:101] test4.del_val(0, 2)? = false
-- loop test4 rev
16 = 3
16 = 2
16 = 1
13 = 32
10 = 5
10 = 0
0 = 6
dup(16) 1
dup(16) 2
dup(16) 3
Szybkie odczyty i zapisy
Jeśli chcemy po prostu odczytać lub zapisać pojedynczy wiersz danych, możemy użyć syntaktycznego cukru, jakim jest makro.
Dane do odczytu
r!(Test1.get [2, 3])
Zapisywanie danych
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Wszystko w jednym wierszu, jak napisano w examples/02.rs.
Typy danych
W pliku examples/02 .rs definicja bazy danych wygląda następująco :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
gdzie key i val określają typy danych odpowiednio dla kluczy i wartości.
W przypadku próby zapisania typu danych, który nie odpowiada zdefiniowanemu, zostanie zgłoszony błąd, jak pokazano na poniższym zrzucie ekranu:

Domyślnym typem danych jest Bin można zapisać dowolne dane, które obsługują adres AsRef<[u8]>.
Jeśli kluczem lub wartością jest ciąg znaków utf8, typ danych można ustawić na Str .
Odcytowanie Str spowoduje zwrócenie łańcucha, podobnego do let k:&str = &k;.
Ponadto strona Str implementuje również std::fmt::Display , println!("{}",k) wyświetli czytelny ciąg znaków.
Zaprogramowane typy danych
Oprócz Str i Bin, wrapper zawiera również obsługę danych dla usize, u128, u64, u32, u16, u8, isize, i128, i64, i32, i16, i8, f32, f64.
Flagi bazy danych
Flagi bazy danych dodane do danych w pliku examples/02.rs można zobaczyć na stronie Test4. flag DUPSORT
Baza danych libmdbx posiada szereg flag ( MDBX_db_flags_t ), które można ustawić.
- REVERSEKEY używa odwrotnego porównywania łańcuchów dla kluczy. (przydatne w przypadku używania małych liczb z kodem końcowym jako kluczy)
- DUPSORT używa posortowanych duplikatów, tzn. dopuszcza wiele wartości dla jednego klucza.
- INTEGERKEY Natywny klucz numeryczny uporządkowany bajtowo uint32_t lub uint64_t. klucze muszą mieć ten sam rozmiar i muszą być wyrównane, gdy są przekazywane jako argument.
- DUPFIXED Rozmiar wartości danych musi być taki sam, jeśli używany jest DUPSORT (umożliwia szybkie policzenie liczby wartości).
- DUPSORT i DUPFIXED są wymagane dla INTEGERDUP; wartości są liczbami całkowitymi (podobnie jak w przypadku INTEGERKEY). Wszystkie wartości danych muszą mieć ten sam rozmiar i muszą być wyrównane, gdy są przekazywane jako parametry.
- REVERSEDUP używa DUPSORT; dla wartości danych używane jest odwrotne porównywanie łańcuchów.
- CREATE tworzy bazę danych, jeśli jeszcze nie istnieje (domyślnie dodana).
- DB_ACCEDE Otwiera istniejącą podbazę danych utworzoną przy użyciu flagi unknown.
Ta flaga DB_ACCEDE jest przeznaczona do otwierania istniejących podbaz danych utworzonych z nieznanymi flagami (REVERSEKEY, DUPSORT, INTEGERKEY, DUPFIXED, INTEGERDUP i REVERSEDUP).
W takim przypadku podbaza nie zwróci błędu INCOMPATIBLE, ale zostanie otwarta z flagami użytymi do jej utworzenia, a aplikacja może określić rzeczywiste flagi za pomocą funkcji mdbx_dbi_flags().
DUPSORT: jednemu kluczowi odpowiada więcej niż jedna wartość
DUPSORTOznacza to, że jednemu kluczowi może odpowiadać więcej niż jedna wartość.
Jeśli chcesz ustawić wiele flag, napisz w następujący sposób flag DUPSORT | DUPFIXED
.dup(key) iterator, który zwraca wszystkie wartości odpowiadające kluczowi
Funkcja ta jest dostępna tylko dla baz danych oznaczonych adresem DUPSORT, w których kluczowi może odpowiadać więcej niż jedna wartość.
W przypadku baz danych DUPSORT, get zwraca tylko pierwszą wartość dla tego klucza. Aby uzyskać wszystkie wartości, należy użyć adresu dup.
Domyślne, automatycznie dołączane flagi bazy danych
Jeśli typ danych to u32 / u64 / usize, flaga bazy danych jest dodawana automatycznie. INTEGERKEY .
W przypadku maszyn z kodowaniem małych końcówek inne typy liczb są dodawane automatycznie REVERSEKEY Znacznik bazy danych jest dodawany automatycznie, gdy typem danych jest / / .
Usuwanie danych
.del(key) Usuwanie klawisza
.del(val) Usuwa wartość odpowiadającą kluczowi.
Jeśli baza danych ma ustawioną flagę DUPSORT, wszystkie wartości pod tym kluczem zostaną usunięte.
Zwraca adres true, jeśli jakieś dane zostały usunięte, oraz false, jeśli nie.
.del_val(key,val) Usuwanie dokładnego dopasowania
.del_val(key,val) Usuwa pary klucz-wartość, które dokładnie odpowiadają parametrom wejściowym.
Zwraca adres true, jeśli jakieś dane zostały usunięte, oraz false, jeśli nie.
Traversal
sekwencyjne przechodzenie
Ze względu na wdrożenie std::iter::IntoIterator . można przemieszczać się bezpośrednio w następujący sposób :
for (k, v) in test1
.rev() Odwrócona kolejność
for (k, v) in test4.rev()
Sortowanie
Klucze libmdbx są posortowane w kolejności słownikowej.
Dla liczb bez znaku
są posortowane od najmniejszej do największej, ponieważ flagi bazy danych są dodawane automatycznie (
u32/u64/usizesą dodawane doINTEGERKEY, inne są dodawane doREVERSEKEYw zależności od kodu maszynowego).Dla liczb podpisanych
kolejność jest następująca: najpierw 0, potem wszystkie liczby dodatnie od najmniejszej do największej, a następnie wszystkie liczby ujemne od najmniejszej do największej.
Iteratory interwałowe
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
Uruchom dane wyjściowe z
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/range.mdb
> Test0
# test0.range([1]..)
(Bin([1]), Bin([1, 2]))
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
(Bin([3]), Bin([]))
# test0.range([1, 1]..=[2])
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
-- all
(2, 4)
(2, 9)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.range(1..3)
(2, 4)
(2, 9)
# test1.range(5..2)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
# test1.range(1..=3)
(2, 4)
(2, 9)
(3, 0)
(3, 8)
# test1.range(..3)
(2, 4)
(2, 9)
# test1.range(3..)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.rev_range(..1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
# test1.rev_range(..=1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
> Test2
# test2.range(1..3)
(1, 5)
(2, 4)
# test2.range(1..=3)
(1, 5)
(2, 4)
# test2.range(..3)
(0, 0)
(1, 5)
(2, 4)
# test2.range(2..)
(2, 4)
(9, 1)
# test2.rev_range(..1)
(9, 1)
(2, 4)
# test2.rev_range(2..)
(2, 4)
(1, 5)
(0, 0)
# test2.rev_range(..=1)
(9, 1)
(2, 4)
(1, 5)
.range(begin..end) Interwał Iteracja
W przypadku liczb przedział to przedział liczbowy.
Dla układu dwójkowego można skonstruować taki sam przedział, np.
let begin : &[u8] = &[1,1];
for (k,v) in test0.range(begin..=&[2]) {}
Jeśli adres begin jest większy niż end, zostanie wykonana iteracja wstecz.
Na przykład strona test1.range(5..2) wyświetli następujące dane :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
Nie jest obsługiwana iteracja interwałowa RangeFull tzn. użycie adresu ..nie jest obsługiwane, zamiast tego należy użyć wspomnianego powyżej traversal.
.rev_range Odwrócone interwały
Jeśli chcesz uzyskać odwrócony przedział, który jest mniejszy lub równy pewnej wartości, możesz wykonać następującą czynność
test2.rev_range(2..)
Dane wyjściowe będą następujące
(2, 4)
(1, 5)
(0, 0)
Dla odwróconego przedziału czasowego nie wolno ustawiać jednego z adresów begin lub end, ponieważ jeśli oba są ustawione, zawsze można użyć adresu range(end..begin), aby uzyskać ten sam efekt.
Dostosowywanie typów danych
Kod demonstracyjny jest dostępny na stronie github.com/rmw-lib/mdbx-example/01
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
Dane wyjściowe są następujące
Some(City { name: "BeiJing", lnglat: (11640, 3990) })
W przykładzie typu niestandardowego używamy speedy do przeprowadzenia serializacji ( speedy performance review ).
Implementacja typu niestandardowego FromMdbx oraz ToAsRef można następnie przechowywać pod adresem mdbx.
Jeśli używasz określonej biblioteki serializacyjnej, możesz także dostosować makra atrybutów, aby uprościć proces.
Upraszczanie typów niestandardowych za pomocą makr atrybutów
Implementacja makra atrybutu jest tak prosta, jak mdbx_speedy Kod makra atrybutu jest następujący :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
Zacznij od cargo add mdbx-speedyw swoim własnym projekcie, a następnie możesz szybko dostosować typ (kod demonstracyjny znajduje się na github.com/rmw-lib/mdbx-example/02 ).
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
fn main() -> Result<()> {
// Wypisz numer wersji libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Odczyt i zapis wielowątkowy
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // W 1/65536 części sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nazwa zmiennej bazy danych Env
Test // Test bazy danych
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nazwy zmiennych dla bazy danych ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Szybkie pisanie
w!(Test1.set [2, 3],[4, 5]);
// Szybkie czytanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Wielokrotne operacje na wielu bazach danych w ramach tej samej transakcji
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcja zostanie zrealizowana po zakończeniu zakresu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
use anyhow::Result;
use mdbx::prelude::*;
use mdbx_speedy::MdbxSpeedy;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
Oczywiście wielokrotne wpisywanie adresu #[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)] jest nadal denerwujące, dlatego można użyć derive_alias aby jeszcze bardziej uprościć kod.
Uwaga dotycząca stosowania
Długość klucza
- Minimalny 0, maksymalny ≈ ½ rozmiaru strony (domyślnie 4K, maksymalny rozmiar klucza strony to 2022 bajty), ustawiany podczas inicjalizacji bazy danych
pagesizemoże być skonfigurowany na nie więcej niż65536i musi być potęgą 2.
Przypisy
Wymieniają oni korzyści wynikające z przejścia z LMDB na MDBX.
Początkowo Erigon korzystał z bazy danych BoltDB, następnie dodano obsługę BadgerDB, a w końcu przeprowadzono całkowitą migrację do LMDB. W pewnym momencie napotkaliśmy problemy ze stabilnością spowodowane używaniem LMDB, których twórcy nie przewidzieli. Od tego czasu przyglądamy się dobrze wspieranej pochodnej LMDB, zwanej MDBX, i mamy nadzieję korzystać z jej ulepszeń w zakresie stabilności oraz potencjalnie współpracować w przyszłości. Integracja MDBX została zakończona i nadszedł czas na dalsze testy i dokumentację.
Korzyści wynikające z przejścia z LMDB na MDBX.
Przyrost "przestrzeń (geometria)" plików bazy danych działa prawidłowo. Jest to ważne, zwłaszcza w systemie Windows. W LMDB należy raz z góry określić rozmiar mapy pamięci (obecnie domyślnie używamy 2 TB), a jeśli plik bazy danych wzrośnie ponad ten limit, proces musi zostać ponownie uruchomiony. W systemie Windows ustawienie rozmiaru mapy pamięci na 2 Tb spowodowałoby, że plik bazy danych już na początku miałby rozmiar 2 Tb, co nie jest zbyt wygodne. W systemie MDBX rozmiar mapy pamięci jest zwiększany co 2 Gb. Oznacza to sporadyczne remapowanie, ale zapewnia lepsze wrażenia użytkownika.
MDBX ma bardziej rygorystyczne kontrole dotyczące jednoczesnego korzystania z przetwarzania transakcji oraz nakładających się transakcji odczytu i zapisu w tym samym wątku wykonawczym. Pozwala to na wykrycie niektórych nieoczywistych błędów i sprawia, że zachowanie jest bardziej przewidywalne.
W ciągu ponad 5 lat (od czasu wydzielenia z LMDB) MDBX zgromadził dużą liczbę poprawek bezpieczeństwa i błędów, które, według naszej wiedzy, nadal istnieją w LMDB. Niektóre z nich zostały wykryte podczas naszych testów, a opiekunowie MDBX potraktowali je poważnie i szybko naprawili.Jeśli chodzi o bazy danych, które stale modyfikują dane, tworzą one sporą ilość przestrzeni odzyskiwalnej (w terminologii LMDB nazywanej również "wolną listą"). Musieliśmy wprowadzić poprawki do LMDB, aby usunąć najpoważniejsze niedociągnięcia w obsłudze przestrzeni odzyskiwalnej (analiza). W MDBX zwrócono szczególną uwagę na efektywną obsługę przestrzeni odzyskiwalnej i jak dotąd nie było potrzeby wprowadzania poprawek.
Z naszych testów wynika, że MDBX wypadł nieco lepiej w naszych obciążeniach roboczych.
MDBX ujawnia więcej wewnętrznych danych telemetrycznych - więcej metryk dotyczących tego, co dzieje się wewnątrz bazy danych. Mamy te dane w Grafanie - dzięki nim możemy podejmować lepsze decyzje dotyczące projektowania aplikacji. Na przykład po pełnym przejściu na MDBX (usunięciu obsługi LMDB) wprowadzimy zasadę "commit half full transaction", aby uniknąć przepełnienia/nieprzeciążenia styków dyskowych. Pozwoli to jeszcze bardziej uprościć nasz kod bez wpływu na jego wydajność.
MDBX obsługuje tryb "Wyłącznego otwarcia" - używamy go podczas migracji baz danych, aby uniemożliwić innym czytnikom dostęp do bazy danych podczas procesu migracji.