
Het roestpakket voor libmdbx
De rust wrapper voor de libmdbx database.
Directory :
Citaten
Toen ik 'rmw.link ' schreef, voelde ik dat ik een ingebedde database nodig had.
Vanwege de netwerkdoorvoer die nodig is om vaak op te nemen, te lezen en te schrijven, was sqlite3 te geavanceerd omwille van de prestaties.
Dus een lager niveau key-value database was meer geschikt (lmdb is 10 keer sneller dan sqlite ).

Uiteindelijk heb ik gekozen voor de magische versie van lmdb - mdbx.
Momenteel ondersteunt het bestaande rust pakket van mdbx-rs (mdbx-sys) van mdbx windows niet, dus nam ik de taak op me om een versie te maken die dat wel doet.
Ondersteuning voor het opslaan van aangepaste roesttypes. Ondersteunt multi-threaded toegang.
De database kan worden gedefinieerd in een module met lazy_static en dan eenvoudig worden geïntroduceerd en gebruikt met iets als :
use db::User;
let id = 1234;
let user = r!(User.get id);
Wat is libmdbx?
mdbx is een secundaire database gebaseerd op lmdb, van de Rus Леонид Юрьев (Leonid Yuriev).
lmdb is een supersnelle embedded key-value database.
De full-text zoekmachine MeiliSearch is gebaseerd op lmdb.
Het deep learning-raamwerk caffe gebruikt ook lmdb als gegevensopslag.
mdbx is 30% sneller dan lmdb in de embedded performance test benchmark ioarena.
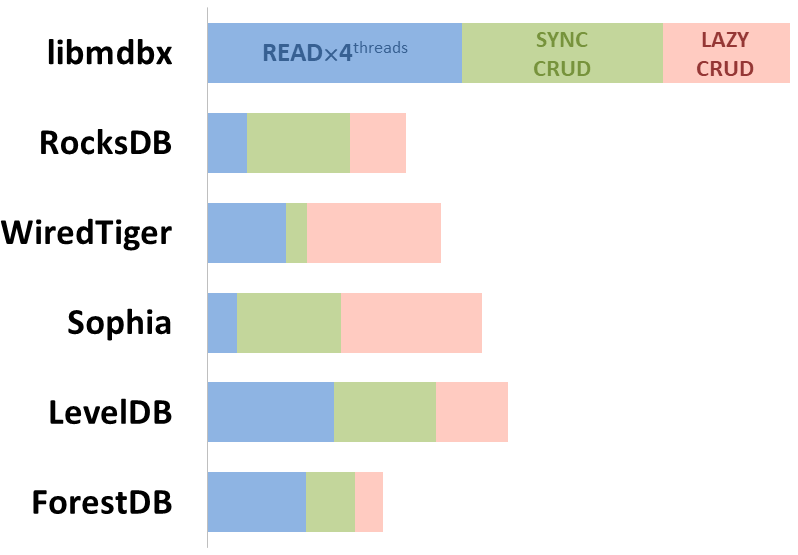
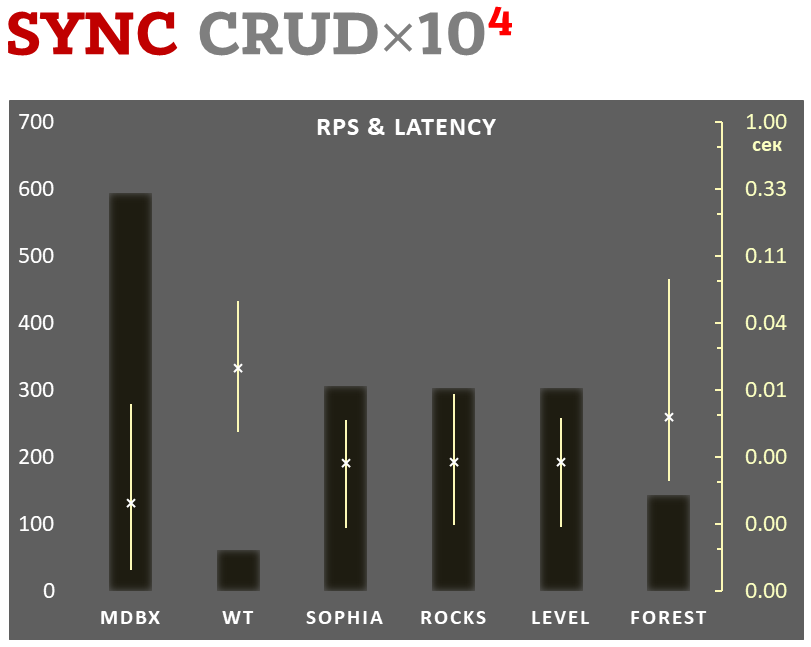
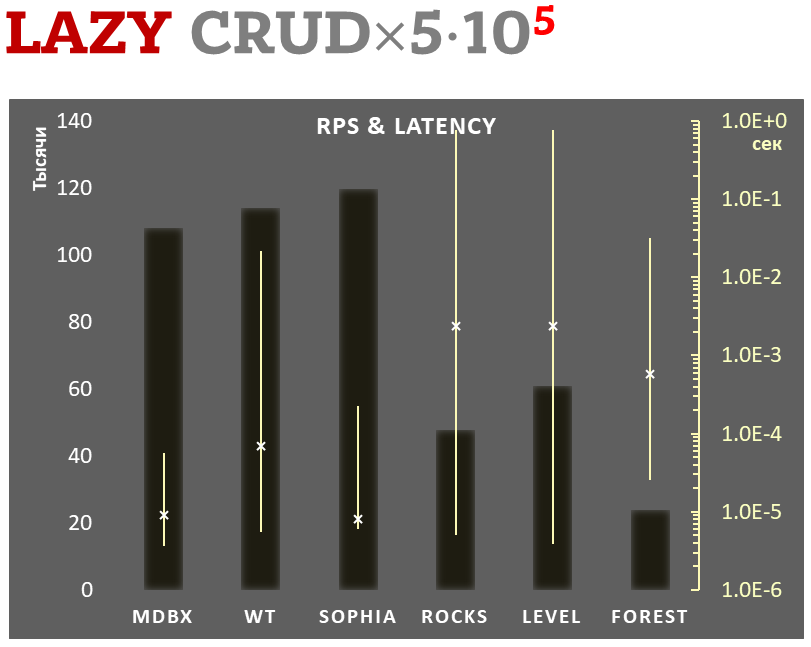
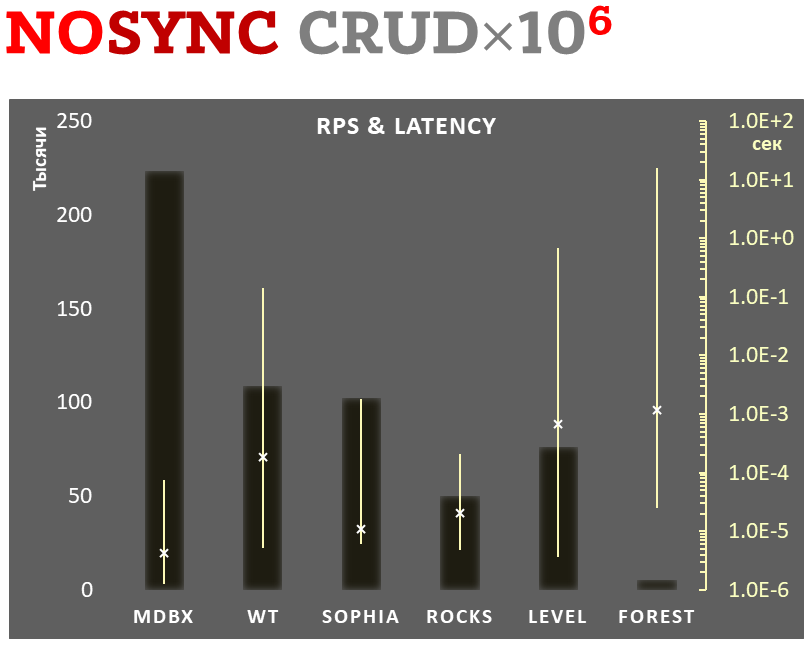
Tegelijkertijd verbetert mdbx veel van de tekortkomingen van lmdb, dus is Erigon (de volgende generatie ethereum client) onlangs overgestapt van LMDB naar MDBX [1].
Tutorials
Hoe het voorbeeld uit te voeren
Kloon eerst de codebase git clone git@github.com:rmw-lib/mdbx.git --depth=1 && cd mdbx
Start dan cargo run --example 01 en het zal examples/01.rs
Als het je eigen project is, draai het dan eerst :
cargo install cargo-edit
cargo add mdbx lazy_static ctor paste
Voorbeeld 1 : Schrijven set(key,val) en lezen .get(key)
Laten we eens kijken naar een eenvoudig voorbeeld/01.rs
Code
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
Voer de uitvoer uit
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/01.mdb
mdbx version https://github.com/erthink/libmdbx/releases/tag/v0.11.2
test1 get Ok(Some(Bin([6])))
[6]
Code omschrijving
env_rw! Definiëren van de database
De code begint met een macro env_rw, die 4 parameters heeft.
De variabele naam van de database omgeving
Geeft als resultaat een object, mdbx:: env:: Config.
We gebruiken de standaardconfiguratie, aangezien Env From<Into<PathBuf>> implementeert, dus het databasepad into() zal volstaan, en de standaardconfiguratie is als volgt.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
max_db Deze instelling kan iedere keer dat de database wordt geopend opnieuw worden ingesteld, maar een te hoge instelling zal de prestaties beïnvloeden, stel hem gewoon in zoals nodig.
Zie de libmdbx documentatie voor de betekenis van de andere parameters.
De naam van de database read transactie macro, de standaard waarde is
rDe naam van de database schrijf transactie macro, de standaard waarde is
w
De parameters 3 en 4 kunnen worden weggelaten om de standaardwaarden te gebruiken.
Macro uitbreiding
Als je wilt zien wat de macro magie doet, kun je de cargo expand --example 01 macro gebruiken om het uit te breiden, die eerst geïnstalleerd moet worden. cargo install cargo-expand
Een screenshot van de uitgebreide code is hieronder te zien.

hoe dan ook en lazy_static
In de uitgebreide schermafbeelding kunt u zien dat lazy_static en anyhowworden gebruikt.
hoe dan ook is de foutafhandeling bibliotheek voor roest.
lazy_static is een statische variabele met vertraagde initialisatie.
Deze twee bibliotheken zijn heel gewoon en ik zal er niet op ingaan.
De macro mdbx!
mdbx! is een procedure macro.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
De eerste regel is de variabele naam van de database omgeving
De tweede regel is de naam van de database
Er kan meer dan één database zijn, één regel voor elke
Draden en transacties
De bovenstaande code demonstreert multi-threaded lezen en schrijven.
Het is belangrijk op te merken dat er slechts één transactie tegelijk in dezelfde thread kan zijn; als een thread meer dan één transactie open heeft staan, zal het programma crashen.
De transactie zal worden vastgelegd aan het einde van het toepassingsgebied.
Binaire gegevens lezen en schrijven
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
set is een schrijven, get is een lezen, en elk object dat implementeert AsRef<[u8]> object naar de database kan worden geschreven.
get Wat eruit komt is Ok(Some(Bin([6])))dat kan worden omgezet in &[u8].
Voorbeeld 2: Datatypes, databaseflags, wissen, traverseren
Laten we eens kijken naar het tweede voorbeeld/02.rs:
In dit voorbeeld wordt env_rw! weggelaten en worden het derde en vierde argument ( r, w) weggelaten.
Code
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
Voer de uitvoer uit
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/02.mdb
u16::from_le_bytes(Bin([4, 5])) = 1284
-- loop test1
[2] = [3]
[2, 3] = [4, 5]
[8, 1] = [9]
[9] = [10, 12]
[97, 98, 99] = [48, 49, 50]
[114, 109, 119, 46, 108, 105, 110, 107] = [68, 111, 119, 110, 32, 119, 105, 116, 104, 32, 68, 97, 116, 97, 32, 72, 101, 103, 101, 109, 111, 110, 121]
[examples/02.rs:57] test1.del_val([8, 1], [3])? = false
[examples/02.rs:58] test1.get([8, 1])?.unwrap() = Bin(
[
9,
],
)
[examples/02.rs:59] test1.del_val([8, 1], [9])? = true
[examples/02.rs:60] test1.get([8, 1])? = None
[examples/02.rs:62] test1.del([9])? = true
[examples/02.rs:63] test1.get([9])? = None
[examples/02.rs:64] test1.del([9])? = false
-- loop test2
abc = 012
rmw.link = Down with Data Hegemony
-- loop test3
0 = 6
10 = 5
13 = 32
16 = 32
-15 = 6
-12 = 6
-10 = 6
[examples/02.rs:100] test4.del_val(0, 2)? = true
[examples/02.rs:101] test4.del_val(0, 2)? = false
-- loop test4 rev
16 = 3
16 = 2
16 = 1
13 = 32
10 = 5
10 = 0
0 = 6
dup(16) 1
dup(16) 2
dup(16) 3
Snel lezen en schrijven
Als we slechts een enkele regel gegevens willen lezen of schrijven, kunnen we de syntactische suiker van de macro gebruiken.
Lees gegevens
r!(Test1.get [2, 3])
Gegevens schrijven
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Alles in één regel, zoals geschreven in examples/02.rs.
Gegevenstypen
In voorbeelden/02 .rs, ziet de database definitie er als volgt uit :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
waarbij key en val de gegevenstypes voor respectievelijk sleutels en waarden definiëren.
Als u probeert een gegevenstype te schrijven dat niet overeenkomt met het gedefinieerde type, zal een fout worden gemeld, zoals in de schermafbeelding hieronder:

Het standaard gegevenstype is Bin kunnen alle gegevens die AsRef<[u8]> implementeren, worden geschreven.
Als de sleutel of waarde een utf8 string is, kan het gegevenstype worden ingesteld op Str .
Als je Str derefereert, krijg je een string terug, vergelijkbaar met let k:&str = &k;.
Bovendien implementeert Str ook std::fmt::Display , println!("{}",k) zal een leesbare string uitvoeren.
Vooraf ingestelde gegevenstypen
Naast Str en Bin heeft de wrapper ook gegevensondersteuning voor usize, u128, u64, u32, u16, u8, isize, i128, i64, i32, i16, i8, f32, f64.
Databank vlaggen
U kunt de databaseflaggen zien die zijn toegevoegd aan de gegevens in examples/02.rs op Test4 flag DUPSORT
De libmdbx database heeft een aantal vlaggen ( MDBX_db_flags_t ) die kunnen worden ingesteld.
- REVERSEKEY gebruikt omgekeerde string-vergelijking voor sleutels. (nuttig bij gebruik van kleine eindgecodeerde nummers als toetsen)
- DUPSORT gebruikt gesorteerde duplicaten, d.w.z. staat meerdere waarden voor een sleutel toe.
- INTEGERKEY Native byte geordende numerieke sleutel uint32_t of uint64_t. sleutels moeten dezelfde grootte hebben en moeten uitgelijnd zijn wanneer ze als argumenten worden doorgegeven.
- DUPFIXED De grootte van de gegevenswaarden moet gelijk zijn als DUPSORT wordt gebruikt (maakt een snelle telling van het aantal waarden mogelijk).
- DUPSORT en DUPFIXED zijn vereist voor INTEGERDUP; de waarden zijn gehele getallen (vergelijkbaar met INTEGERKEY). De gegevenswaarden moeten allemaal dezelfde grootte hebben en moeten worden uitgelijnd wanneer ze als parameter worden doorgegeven.
- REVERSEDUP gebruikt DUPSORT; omgekeerde stringvergelijking wordt gebruikt voor gegevenswaarden.
- CREATE creëert de DB als die niet bestaat (standaard toegevoegd).
- DB_ACCEDE Opent een bestaande subdatabase die is aangemaakt met de vlag onbekend.
Deze vlag DB_ACCEDE is bedoeld om bestaande subdatabanken te openen die zijn aangemaakt met onbekende vlaggen (REVERSEKEY, DUPSORT, INTEGERKEY, DUPFIXED, INTEGERDUP en REVERSEDUP).
In dit geval zal de subdatabase geen INCOMPATIBLE-fout teruggeven, maar zal ze geopend worden met de vlaggen die gebruikt werden om ze aan te maken, en de toepassing kan dan de eigenlijke vlaggen bepalen met mdbx_dbi_flags().
DUPSORT : Een sleutel komt overeen met meer dan een waarde
DUPSORTbetekent dat een sleutel met meer dan één waarde kan corresponderen.
Als u meerdere vlaggen wilt instellen, schrijft u als volgt flag DUPSORT | DUPFIXED
.dup(key) iterator die alle waarden teruggeeft die corresponderen met een sleutel
Deze functie is alleen beschikbaar voor databases gemarkeerd met DUPSORT waar een sleutel kan corresponderen met meer dan één waarde.
Voor DUPSORT databases, get geeft alleen de eerste waarde voor deze sleutel. Om alle waarden te krijgen, gebruik dup.
Standaard automatisch toegevoegde databankvlaggen
Wanneer het gegevenstype u32 / u64 / usize is, wordt de databaseflag automatisch toegevoegd INTEGERKEY .
Op machines met small-end codering worden andere numerieke types automatisch toegevoegd REVERSEKEY De databaseflag wordt automatisch toegevoegd wanneer het gegevenstype / / is.
Gegevens verwijderen
.del(key) Een toets verwijderen
.del(val) Verwijdert de waarde die overeenkomt met een sleutel.
Als de database de vlag DUPSORTheeft, zullen alle waarden onder deze sleutel worden verwijderd.
Geeft trueterug als gegevens zijn verwijderd, en falseals dat niet het geval is.
.del_val(key,val) Exacte overeenkomst wissen
.del_val(key,val) Verwijdert sleutel-waardeparen die precies overeenkomen met de invoerparameters.
Geeft trueterug als gegevens zijn verwijderd, en falseals dat niet het geval is.
Traversal
sequentiële traversal
Vanwege de uitvoering van std::iter::IntoIterator . kunt u rechtstreeks als volgt oversteken :
for (k, v) in test1
.rev() Omgekeerde volgorde traversal
for (k, v) in test4.rev()
Sorteren
De libmdbx-sleutels zijn gesorteerd in dictionary-volgorde.
Voor niet-ondertekende getallen
worden gesorteerd van klein naar groot omdat de databankvlaggen automatisch worden toegevoegd (
u32/u64/usizeworden toegevoegd aanINTEGERKEY, andere worden toegevoegd aanREVERSEKEYafhankelijk van de machinecode).Voor getekende getallen
de volgorde is: eerst 0, dan alle positieve getallen van klein naar groot, dan alle negatieve getallen van klein naar groot.
Interval iteratoren
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
Voer de uitvoer van
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/range.mdb
> Test0
# test0.range([1]..)
(Bin([1]), Bin([1, 2]))
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
(Bin([3]), Bin([]))
# test0.range([1, 1]..=[2])
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
-- all
(2, 4)
(2, 9)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.range(1..3)
(2, 4)
(2, 9)
# test1.range(5..2)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
# test1.range(1..=3)
(2, 4)
(2, 9)
(3, 0)
(3, 8)
# test1.range(..3)
(2, 4)
(2, 9)
# test1.range(3..)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.rev_range(..1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
# test1.rev_range(..=1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
> Test2
# test2.range(1..3)
(1, 5)
(2, 4)
# test2.range(1..=3)
(1, 5)
(2, 4)
# test2.range(..3)
(0, 0)
(1, 5)
(2, 4)
# test2.range(2..)
(2, 4)
(9, 1)
# test2.rev_range(..1)
(9, 1)
(2, 4)
# test2.rev_range(2..)
(2, 4)
(1, 5)
(0, 0)
# test2.rev_range(..=1)
(9, 1)
(2, 4)
(1, 5)
.range(begin..end) Interval Iteratie
Voor getallen is een interval een numeriek interval.
Voor binair kan hetzelfde interval worden geconstrueerd, bv.
let begin : &[u8] = &[1,1];
for (k,v) in test0.range(begin..=&[2]) {}
Als begin groter is dan end, zal het terugwaarts gaan.
Bijvoorbeeld, test1.range(5..2) zal het volgende uitvoeren :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
Interval iteratie wordt niet ondersteund RangeFull .. wordt niet ondersteund, gebruik in plaats daarvan de hierboven genoemde traversal.
.rev_range Omgekeerde intervallen
Indien je een geïnverteerd interval wil bekomen dat kleiner of gelijk is aan een waarde, kan je dit doen
test2.rev_range(2..)
Zet de uitgang
(2, 4)
(1, 5)
(0, 0)
Eén van begin of end mag niet zijn ingesteld voor het omgekeerde interval; want als beide zijn ingesteld, kunt u altijd range(end..begin) gebruiken om hetzelfde effect te bereiken.
Aanpassen van gegevenstypen
De demo code is beschikbaar op github.com/rmw-lib/mdbx-example/01
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
De output is als volgt
Some(City { name: "BeiJing", lnglat: (11640, 3990) })
In het aangepaste type voorbeeld, gebruiken we speedy om de serialisatie te doen ( speedy performance review ).
De aangepaste type-implementatie FromMdbx en ToAsRef kan dan worden opgeslagen op mdbx.
Als u een specifieke serialisatiebibliotheek gebruikt, kunt u ook attribuutmacro 's aanpassen om het proces te vereenvoudigen.
Aangepaste types vereenvoudigen met attribuutmacro's
Het implementeren van een attribuut macro is zo simpel als mdbx_speedy De attribuut-macrocode is als volgt :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
Begin met cargo add mdbx-speedyin je eigen project en dan kun je het type snel aanpassen (zie github.com/rmw-lib/mdbx-example/02 voor demo code).
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
fn main() -> Result<()> {
// Geef het versienummer van libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Multi-threaded lezen en schrijven
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536ste van een seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Variabele naam van de database Env
Test // Database Test
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Namen van variabelen voor database NLV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Snel schrijven
w!(Test1.set [2, 3],[4, 5]);
// Snel lezen
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Meerdere bewerkingen op meerdere databases in dezelfde transactie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// De transactie zal worden vastgelegd aan het einde van het toepassingsgebied
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
use anyhow::Result;
use mdbx::prelude::*;
use mdbx_speedy::MdbxSpeedy;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
Natuurlijk is het nog steeds vervelend om herhaaldelijk #[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)] te schrijven, dus je kunt derive_alias om de code verder te vereenvoudigen.
Opmerking over het gebruik van
De lengte van de sleutel
- Minimum 0, maximum ≈ ½ paginagrootte (standaard 4K paginasleutel maximumgrootte is 2022 bytes), ingesteld bij het initialiseren van de databank
pagesizekan worden ingesteld op niet meer dan65536en moet een macht van 2 zijn.
Voetnoten
Zij noemen de voordelen van de overschakeling van LMDB op MDBX.
Erigon begon met een BoltDB database backend, voegde vervolgens ondersteuning voor BadgerDB toe, en migreerde uiteindelijk volledig naar LMDB. op een gegeven moment liepen we tegen stabiliteitsproblemen aan die werden veroorzaakt door ons gebruik van LMDB die niet waren voorzien door de makers. Sindsdien hebben wij gekeken naar een goed ondersteunde afgeleide van LMDB genaamd MDBX en hopen wij gebruik te maken van hun stabiliteitsverbeteringen en mogelijk meer samen te werken in de toekomst. De integratie van MDBX is nu voltooid en het is tijd voor meer testen en documentatie.
Voordelen van de overschakeling van LMDB naar MDBX.
De groei "ruimte (geometrie)" van de databasebestanden werkt naar behoren. Dit is belangrijk, vooral op Windows. In LMDB moet men de grootte van de geheugenmap eenmalig vooraf opgeven (momenteel gebruiken wij standaard 2Tb) en als het databasebestand boven deze limiet groeit, moet het proces opnieuw worden opgestart. Op Windows zou het instellen van de geheugenkaart grootte op 2Tb het database bestand 2Tb groot maken om mee te beginnen, wat niet erg handig is. In MDBX wordt de geheugenkaartgrootte in stappen van 2Gb vergroot. Dit betekent af en toe remapping, maar resulteert in een betere gebruikerservaring.
MDBX heeft strengere controles op gelijktijdig gebruik van transactieverwerking en overlappende lees- en schrijftransacties in dezelfde thread van uitvoering. Hierdoor kunnen we sommige niet voor de hand liggende fouten opsporen en wordt het gedrag voorspelbaarder.
In meer dan 5 jaar (sinds het werd gescheiden van LMDB), heeft MDBX een groot aantal veiligheids- en heisenbug-fixes verzameld die, voor zover wij weten, nog steeds bestaan in LMDB. Sommige van deze problemen zijn tijdens onze tests ontdekt, en de beheerders van MDBX hebben ze serieus genomen en onmiddellijk verholpen.Databanken die voortdurend gegevens wijzigen, creëren een aanzienlijke hoeveelheid ruimte die kan worden teruggewonnen (ook bekend als "freelist" in LMDB-terminologie). Wij hebben LMDB moeten patchen om de ernstigste tekortkomingen in de behandeling van reclaimable space (analyse) te verhelpen. MDBX heeft bijzondere aandacht besteed aan de efficiënte behandeling van reclaimable space en behoefde tot dusver niet te worden gep atcht.
Op basis van onze tests presteerde MDBX iets beter op onze werklasten.
MDBX geeft meer interne telemetriegegevens vrij - meer metriek over wat er in de database gebeurt. En we hebben deze gegevens in Grafana - om betere beslissingen te nemen over het ontwerp van applicaties. Na de volledige overgang naar MDBX (waarbij de ondersteuning voor LMDB wordt verwijderd) zullen wij bijvoorbeeld een "commit half full transaction"-beleid invoeren om overflow/unoverflow van schijfcontacten te voorkomen. Dit zal onze code verder vereenvoudigen zonder de prestaties te beïnvloeden.
MDBX ondersteunt "Exclusive open" mode - wij gebruiken dit voor databankmigraties om te voorkomen dat andere readers de databank kunnen benaderen tijdens het migratieproces.