
Il pacchetto rust per libmdbx
Il wrapper rust per il database libmdbx.
Directory :
Citazioni
Mentre scrivevo 'rmw.link ', ho sentito che avevo bisogno di un database incorporato.
A causa del throughput di rete coinvolto nella registrazione, lettura e scrittura frequente, sqlite3 era troppo avanzato per le preoccupazioni di performance.
Quindi un database a valore chiave di livello inferiore era più appropriato (lmdb è 10 volte più veloce di sqlite ).

Alla fine, ho optato per la versione magica di lmdb - mdbx.
Attualmente, il pacchetto esistente rust di mdbx-rs (mdbx-sys) da mdbx non supporta windows, così mi sono preso la responsabilità di pacchettizzare una versione con supporto per windows.
Supporto per la memorizzazione di tipi di ruggine personalizzati. Supporta l'accesso multi-thread.
Il database può essere definito in un modulo usando lazy_static e poi semplicemente introdotto e usato con qualcosa come :
use db::User;
let id = 1234;
let user = r!(User.get id);
Cos'è libmdbx?
mdbx è un database secondario basato su lmdb, dal russo Леонид Юрьев (Leonid Yuriev).
lmdb è un super-veloce database integrato chiave-valore.
Il motore di ricerca full-text MeiliSearch è basato su lmdb.
Anche il framework di apprendimento profondo caffe usa lmdb come archivio di dati.
mdbx è il 30% più veloce di lmdb nel benchmark di prestazioni embedded ioarena.
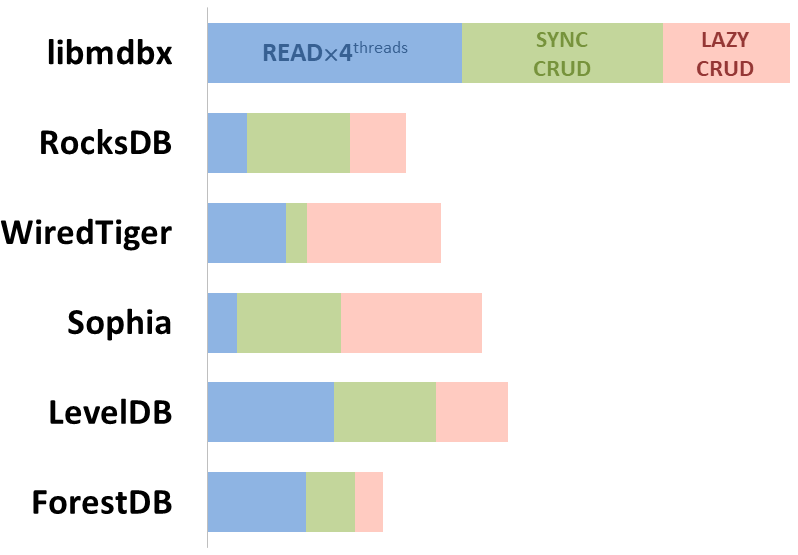
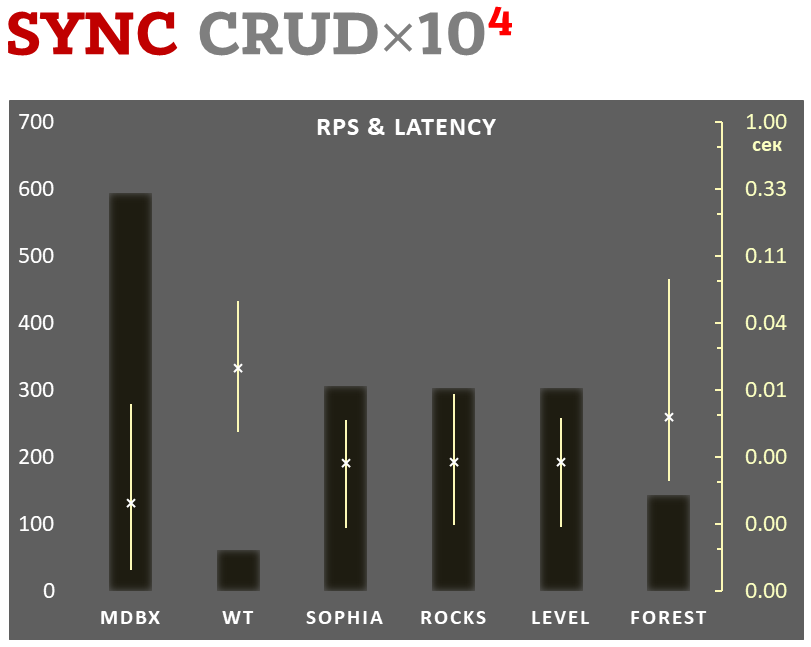
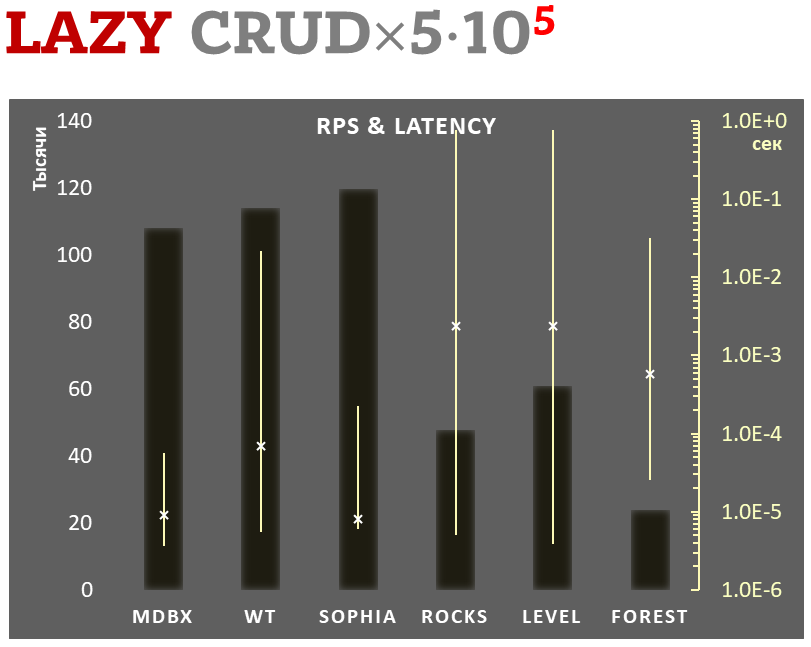
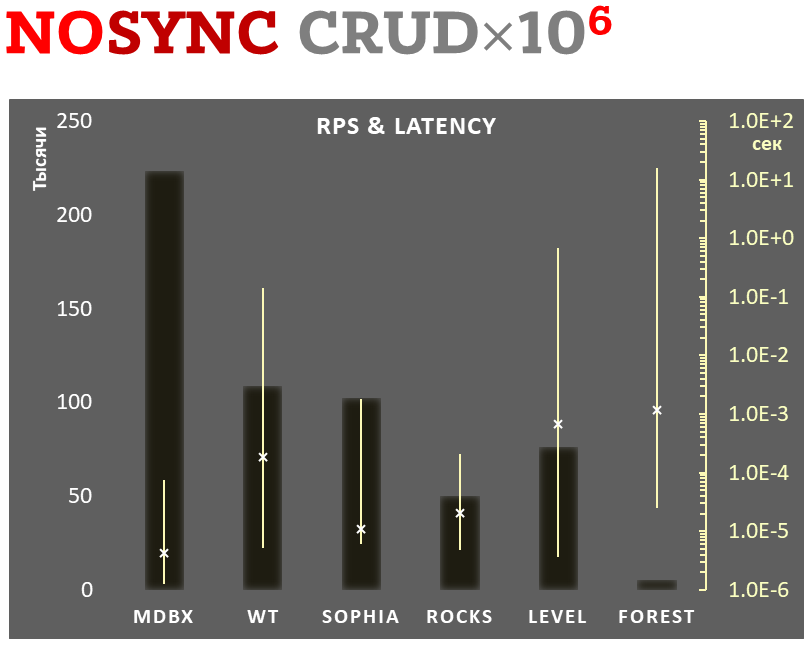
Allo stesso tempo, mdbx migliora molte delle carenze di lmdb, così Erigon (il client ethereum di prossima generazione) è recentemente passato da LMDB a MDBX [^erigon].
Tutorial
Come eseguire l'esempio
Prima clona il codice base git clone git@github.com:rmw-lib/mdbx.git --depth=1 && cd mdbx
Poi eseguite cargo run --example 01 ed eseguirà examples/01.rs
Se si tratta di un tuo progetto, eseguilo prima:
cargo install cargo-edit
cargo add mdbx lazy_static ctor paste
Esempio 1: scrivere set(key,val) e leggere .get(key)
Guardiamo un semplice esempio/01.rs
Codice
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
Eseguire l'uscita
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/01.mdb
mdbx version https://github.com/erthink/libmdbx/releases/tag/v0.11.2
test1 get Ok(Some(Bin([6])))
[6]
Descrizione del codice
env_rw! Definire il database
Il codice inizia con una macro env_rw, che ha 4 parametri.
Il nome della variabile dell'ambiente del database
Restituisce un oggetto, mdbx:: env:: Config.
Usiamo la configurazione predefinita, poiché Env implementa From<Into<PathBuf>>, quindi il percorso del database into() andrà bene, e la configurazione predefinita è la seguente.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
max_db Questa impostazione può essere reimpostata ogni volta che il database viene aperto, ma impostarla troppo influenzerà le prestazioni, basta impostarla come richiesto.
Vedere la documentazione di libmdbx per il significato degli altri parametri.
Il nome della macro della transazione di lettura del database, il valore predefinito è
rIl nome della macro della transazione di scrittura del database, il valore predefinito è
w
I parametri 3 e 4 possono essere omessi per utilizzare i valori predefiniti.
Espansione macro
Se vuoi vedere cosa sta facendo la magia della macro, puoi usare la macro cargo expand --example 01 per espanderla, che deve essere installata prima. cargo install cargo-expand
Uno screenshot del codice espanso è mostrato qui sotto.

comunque e lazy_static
Dalla schermata estesa, si può vedere che lazy_static e anyhowsono utilizzati.
è la libreria di gestione degli errori per rust.
lazy_static è una variabile statica con inizializzazione ritardata.
Queste due biblioteche sono molto comuni e non mi addentrerò in esse.
La macro mdbx!
mdbx! è una macro di procedura.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
La prima linea è il nome della variabile dell'ambiente del database
La seconda linea è il nome del database
Ci può essere più di un database, una linea per ogni
Thread e transazioni
Il codice qui sopra dimostra la lettura e la scrittura multi-thread.
È importante notare che ci può essere solo una transazione nello stesso thread in qualsiasi momento, se un thread ha più di una transazione aperta il programma andrà in crash.
La transazione sarà impegnata alla fine dell'ambito.
Lettura e scrittura di dati binari
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
set è una scrittura, get è una lettura, e qualsiasi oggetto che implementa AsRef<[u8]> può essere scritto nel database.
get Quello che viene fuori è Ok(Some(Bin([6])))che può essere convertito in &[u8].
Esempio 2: tipi di dati, flag del database, cancellazione, attraversamento
Guardiamo il secondo esempio/02.rs :
In questo esempio, env_rw! è omesso e il terzo e quarto argomento ( r, w) sono omessi.
Codice
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
Eseguire l'uscita
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/02.mdb
u16::from_le_bytes(Bin([4, 5])) = 1284
-- loop test1
[2] = [3]
[2, 3] = [4, 5]
[8, 1] = [9]
[9] = [10, 12]
[97, 98, 99] = [48, 49, 50]
[114, 109, 119, 46, 108, 105, 110, 107] = [68, 111, 119, 110, 32, 119, 105, 116, 104, 32, 68, 97, 116, 97, 32, 72, 101, 103, 101, 109, 111, 110, 121]
[examples/02.rs:57] test1.del_val([8, 1], [3])? = false
[examples/02.rs:58] test1.get([8, 1])?.unwrap() = Bin(
[
9,
],
)
[examples/02.rs:59] test1.del_val([8, 1], [9])? = true
[examples/02.rs:60] test1.get([8, 1])? = None
[examples/02.rs:62] test1.del([9])? = true
[examples/02.rs:63] test1.get([9])? = None
[examples/02.rs:64] test1.del([9])? = false
-- loop test2
abc = 012
rmw.link = Down with Data Hegemony
-- loop test3
0 = 6
10 = 5
13 = 32
16 = 32
-15 = 6
-12 = 6
-10 = 6
[examples/02.rs:100] test4.del_val(0, 2)? = true
[examples/02.rs:101] test4.del_val(0, 2)? = false
-- loop test4 rev
16 = 3
16 = 2
16 = 1
13 = 32
10 = 5
10 = 0
0 = 6
dup(16) 1
dup(16) 2
dup(16) 3
Lettura e scrittura veloce
Se vogliamo semplicemente leggere o scrivere una singola linea di dati, possiamo usare lo zucchero sintattico di una macro.
Leggere i dati
r!(Test1.get [2, 3])
Scrittura dei dati
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Tutto in una riga, come scritto in esempi/02.rs.
Tipi di dati
In esempi/02 .rs, la definizione del database appare così:
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
dove key e val definiscono i tipi di dati per le chiavi e i valori rispettivamente.
Se si cerca di scrivere un tipo di dati che non corrisponde a quello definito, verrà riportato un errore, come mostrato nella schermata qui sotto:

Il tipo di dati predefinito è Bin , qualsiasi dato che implementa AsRef<[u8]> può essere scritto.
Se la chiave o il valore è una stringa utf8, il tipo di dati può essere impostato a Str .
La de-citazione di Str restituirà una stringa, simile a let k:&str = &k;.
Inoltre, Str implementa anche std::fmt::Display , println!("{}",k) produrrà una stringa leggibile.
Tipi di dati preimpostati
Oltre a Str e Bin, il wrapper ha anche il supporto dati per usize, u128, u64, u32, u16, u8, isize, i128, i64, i32, i16, i8, f32, f64.
Bandiere del database
Potete vedere i flag del database aggiunti ai dati in examples/02.rs su Test4 flag DUPSORT
Il database libmdbx ha una serie di flag ( MDBX_db_flags_t ) che può essere impostato.
- REVERSEKEY usa il confronto inverso delle stringhe per le chiavi. (utile quando si usano piccoli numeri con codice finale come chiavi)
- DUPSORT usa duplicati ordinati, cioè permette valori multipli per una chiave.
- INTEGERKEY Chiave numerica nativa ordinata in byte uint32_t o uint64_t. le chiavi devono avere la stessa dimensione e devono essere allineate quando vengono passate come argomento.
- DUPFIXED La dimensione dei valori dei dati deve essere la stessa se si usa DUPSORT (permette un rapido conteggio del numero di valori).
- DUPSORT e DUPFIXED sono richiesti per INTEGERDUP; i valori sono interi (simili a INTEGERKEY). I valori dei dati devono avere tutti la stessa dimensione e devono essere allineati quando vengono passati come parametri.
- REVERSEDUP usa DUPSORT; il confronto inverso delle stringhe viene usato per i valori dei dati.
- CREATE crea il DB se non esiste (aggiunto di default).
- DB_ACCEDE Apre un sottobase esistente creato con il flag sconosciuto.
Questo flag DB_ACCEDE è destinato ad aprire sottobasi esistenti create con flag sconosciuti (REVERSEKEY, DUPSORT, INTEGERKEY, DUPFIXED, INTEGERDUP e REVERSEDUP).
In questo caso, il sottodatabase non restituirà un errore INCOMPATIBLE, ma sarà aperto con le bandiere usate per crearlo, e l'applicazione può poi determinare le bandiere effettive con mdbx_dbi_flags().
DUPSORT : una chiave corrisponde a più di un valore
DUPSORTsignifica che una chiave può corrispondere a più di un valore.
Se volete impostare più flag, scrivete come segue flag DUPSORT | DUPFIXED
.dup(key) che restituisce tutti i valori corrispondenti a una chiave
Questa funzione è disponibile solo per i database contrassegnati da DUPSORT dove una chiave può corrispondere a più di un valore.
Per i database DUPSORT, get restituisce solo il primo valore per questa chiave. Per ottenere tutti i valori, usate dup.
Flags di database aggiunti automaticamente di default
Quando il tipo di dati è u32 / u64 / usize, il flag del database viene aggiunto automaticamente. INTEGERKEY .
Su macchine con codifica small-end, altri tipi numerici sono aggiunti automaticamente REVERSEKEY Il flag del database viene aggiunto automaticamente quando il tipo di dati è / / .
Cancellare i dati
.del(key) Cancellare una chiave
.del(val) Cancella il valore corrispondente a una chiave.
Se il database ha il flag DUPSORT, tutti i valori sotto questa chiave saranno cancellati.
Restituisce truese qualche dato è stato cancellato, e falsein caso contrario.
.del_val(key,val) Cancellazione con corrispondenza esatta
.del_val(key,val) Elimina le coppie chiave-valore che corrispondono esattamente ai parametri di input.
Restituisce truese qualche dato è stato cancellato, e falsein caso contrario.
Traversata
traversata sequenziale
A causa dell'implementazione di std::iter::IntoIterator . si può attraversare direttamente come segue:
for (k, v) in test1
.rev() Attraversamento dell'ordine inverso
for (k, v) in test4.rev()
Ordinamento
Le chiavi libmdbx sono ordinate in ordine di dizionario.
Per i numeri senza segno
sono ordinati dal più piccolo al più grande perché i flag del database sono aggiunti automaticamente (
u32/u64/usizesono aggiunti aINTEGERKEY, altri sono aggiunti aREVERSEKEYa seconda del codice macchina).Per i numeri firmati
l'ordine è: prima lo 0, poi tutti i numeri positivi dal più piccolo al più grande, poi tutti i numeri negativi dal più piccolo al più grande.
Intervalli iteratori
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
Esegui l'output di
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/range.mdb
> Test0
# test0.range([1]..)
(Bin([1]), Bin([1, 2]))
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
(Bin([3]), Bin([]))
# test0.range([1, 1]..=[2])
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
-- all
(2, 4)
(2, 9)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.range(1..3)
(2, 4)
(2, 9)
# test1.range(5..2)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
# test1.range(1..=3)
(2, 4)
(2, 9)
(3, 0)
(3, 8)
# test1.range(..3)
(2, 4)
(2, 9)
# test1.range(3..)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.rev_range(..1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
# test1.rev_range(..=1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
> Test2
# test2.range(1..3)
(1, 5)
(2, 4)
# test2.range(1..=3)
(1, 5)
(2, 4)
# test2.range(..3)
(0, 0)
(1, 5)
(2, 4)
# test2.range(2..)
(2, 4)
(9, 1)
# test2.rev_range(..1)
(9, 1)
(2, 4)
# test2.rev_range(2..)
(2, 4)
(1, 5)
(0, 0)
# test2.rev_range(..=1)
(9, 1)
(2, 4)
(1, 5)
.range(begin..end) Intervallo di iterazione
Per i numeri, un intervallo è un intervallo numerico.
Per il binario, lo stesso intervallo può essere costruito, ad esempio
let begin : &[u8] = &[1,1];
for (k,v) in test0.range(begin..=&[2]) {}
Se begin è maggiore di end, itererà all'indietro.
Per esempio, test1.range(5..2) produrrà il seguente output :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
L'iterazione a intervalli non è supportata RangeFull , cioè l'uso di ..non è supportato, si prega di utilizzare invece il traversal menzionato sopra.
.rev_range Intervalli invertiti
Se volete ottenere un intervallo invertito che sia minore o uguale a un valore, potete fare così
test2.rev_range(2..)
L'output sarà
(2, 4)
(1, 5)
(0, 0)
Uno di begin o end non deve essere impostato per l'intervallo invertito; perché se entrambi sono impostati, si può sempre usare range(end..begin) per ottenere lo stesso effetto.
Personalizzazione dei tipi di dati
Il codice demo è disponibile su github.com/rmw-lib/mdbx-example/01
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
L'output è il seguente
Some(City { name: "BeiJing", lnglat: (11640, 3990) })
Nell'esempio del tipo personalizzato, usiamo speedy per fare la serializzazione ( speedy performance review ).
Implementazione del tipo personalizzato FromMdbx e ToAsRef può quindi essere conservato su mdbx.
Se state usando una specifica libreria di serializzazione, potete anche personalizzare le macro degli attributi per semplificare il processo.
Semplificare i tipi personalizzati con le macro di attributi
Implementare una macro di attributi è semplice come mdbx_speedy Il codice della macro attributo è il seguente:
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
Inizia con cargo add mdbx-speedynel tuo progetto e poi puoi personalizzare rapidamente il tipo (vedi github.com/rmw-lib/mdbx-example/02 per il codice demo).
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
fn main() -> Result<()> {
// Mostra il numero di versione di libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lettura e scrittura multi-threaded
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // In 1/65536 di secondo
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nome della variabile del database Env
Test // Test del database
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Nomi di variabili per il database ITV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Scrittura rapida
w!(Test1.set [2, 3],[4, 5]);
// Lettura rapida
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Operazioni multiple su più database nella stessa transazione
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transazione sarà impegnata alla fine dell'ambito
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
use anyhow::Result;
use mdbx::prelude::*;
use mdbx_speedy::MdbxSpeedy;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
Naturalmente è ancora fastidioso scrivere #[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)] ripetutamente, quindi si può usare derive_alias per semplificare ulteriormente il codice.
Nota sull'uso di
La lunghezza della chiave
- Minimo 0, massimo ≈ ½ dimensione della pagina (dimensione massima della chiave di pagina 4K di default è 2022 byte), impostata quando si inizializza il database
pagesizepuò essere configurato a non più di65536e deve essere una potenza di 2.
Note a piè di pagina
[ Erigon (il client Ethernet di prossima generazione) è recentemente passato da LMDB a MDBX.
Citano i vantaggi della transizione da LMDB a MDBX.
Erigon ha iniziato con un backend di database BoltDB, poi ha aggiunto il supporto per BadgerDB, e infine è migrato completamente a LMDB. a un certo punto ci siamo imbattuti in problemi di stabilità causati dal nostro uso di LMDB che non erano stati previsti dai creatori. Da allora abbiamo guardato un derivato ben supportato di LMDB chiamato MDBX e speriamo di usare i loro miglioramenti di stabilità e potenzialmente collaborare di più in futuro. l'integrazione di MDBX è ora completa ed è tempo di ulteriori test e documentazione.
Vantaggi della transizione da LMDB a MDBX.
La crescita "spazio (geometria)" dei file di database funziona correttamente. Questo è importante, specialmente su Windows. In LMDB si deve specificare la dimensione della mappa di memoria una volta in anticipo (attualmente usiamo 2Tb di default) e se il file del database cresce oltre questo limite, il processo deve essere riavviato. Su Windows, impostare la dimensione della mappa di memoria a 2Tb renderebbe il file del database grande 2Tb per cominciare, il che non è molto conveniente. Su MDBX, la dimensione della mappa di memoria è incrementata in incrementi di 2Gb. Questo significa una rimappatura occasionale, ma si traduce in una migliore esperienza utente.
MDBX ha controlli più severi sull'uso concorrente dell'elaborazione delle transazioni e sulla sovrapposizione di transazioni in lettura e scrittura nello stesso thread di esecuzione. Questo ci permette di individuare alcuni errori non ovvi e rende il comportamento più prevedibile.
In oltre 5 anni (da quando è stato separato da LMDB), MDBX ha accumulato un gran numero di correzioni di sicurezza e di heisenbug che, a nostra conoscenza, esistono ancora in LMDB. Alcuni di questi sono stati scoperti durante i nostri test, e i manutentori di MDBX li hanno presi sul serio e li hanno corretti prontamente.Quando si tratta di database che modificano costantemente i dati, creano una discreta quantità di spazio recuperabile (noto anche come "freelist" nella terminologia LMDB). Abbiamo dovuto patchare LMDB per correggere le carenze più gravi nella gestione dello spazio recuperabile (analisi). MDBX ha prestato particolare attenzione alla gestione efficiente dello spazio recuperabile e, finora, non ha avuto bisogno di essere patchato.
Sulla base dei nostri test, MDBX ha funzionato leggermente meglio sui nostri carichi di lavoro.
MDBX espone più dati di telemetria interna - più metriche su ciò che sta accadendo all'interno del database. E abbiamo questi dati in Grafana - per prendere decisioni migliori sul design delle applicazioni. Per esempio, dopo la transizione completa a MDBX (rimuovendo il supporto per LMDB), implementeremo una politica di "commit half full transaction" per evitare contatti disco overflow/unoverflow. Questo semplificherà ulteriormente il nostro codice senza impattare sulle prestazioni.
MDBX supporta la modalità "Exclusive open" - la usiamo per le migrazioni di database per impedire a qualsiasi altro lettore di accedere al database durante il processo di migrazione.