
Balík rust pre libmdbx
Obal rust pre databázu libmdbx.
Adresár :
Citáty
Pri písaní 'rmw.link ' som mal pocit, že potrebujem vloženú databázu.
Vzhľadom na priepustnosť siete spojenú s častým nahrávaním, čítaním a zápisom bola stránka sqlite3 príliš pokročilá z hľadiska výkonnosti.
Preto bola vhodnejšia nižšia úroveň databázy kľúč-hodnota (lmdb je 10-krát rýchlejšia ako sqlite ).

Nakoniec som sa rozhodol pre magickú verziu lmdb - mdbx.
V súčasnosti existujúci balík rust mdbx-rs (mdbx-sys ) z mdbx nepodporuje windows, preto som sa podujal na vytvorenie balíka s podporou windows.
Podpora ukladania vlastných typov hrdze. Podporuje viacvláknový prístup.
Databázu možno definovať v module pomocou lazy_static a potom ju jednoducho zaviesť a používať pomocou niečoho ako :
use db::User;
let id = 1234;
let user = r!(User.get id);
Čo je libmdbx?
mdbx je sekundárna databáza založená na lmdb, ktorej autorom je ruský Леонид Юрьев (Leonid Juriev).
lmdb je superrýchla vstavaná databáza kľúč-hodnota.
Fulltextový vyhľadávač MeiliSearch je založený na lmdb.
Rámec pre hlboké učenie caffe tiež používa lmdb ako dátové úložisko.
mdbx je o 30 % rýchlejší ako lmdb v benchmarku ioarena na testovanie vstavaného výkonu.
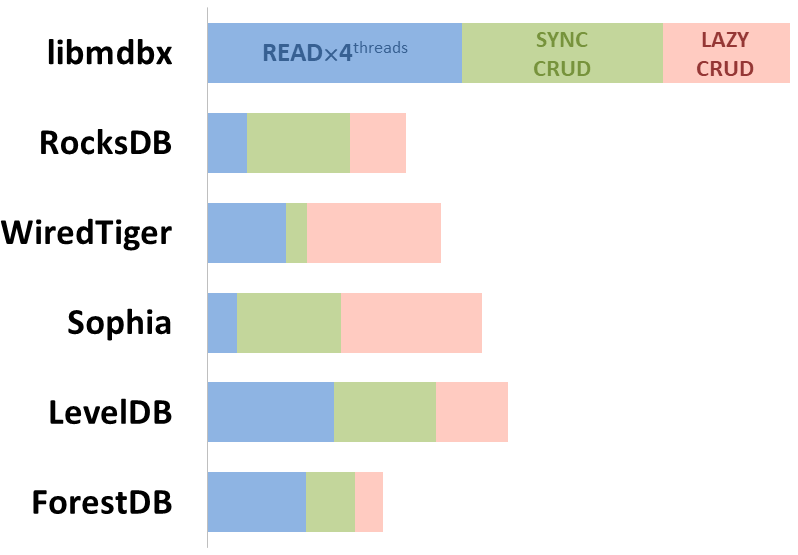
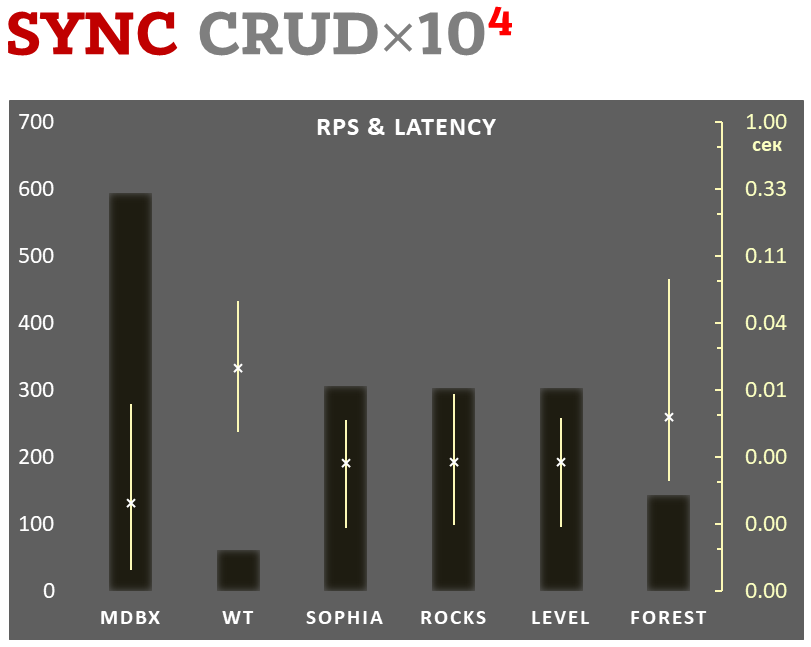
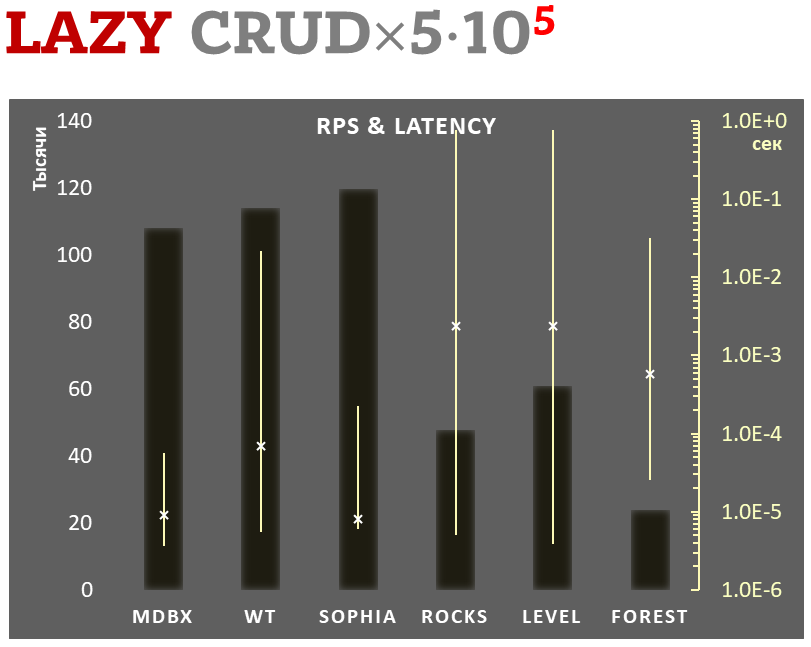
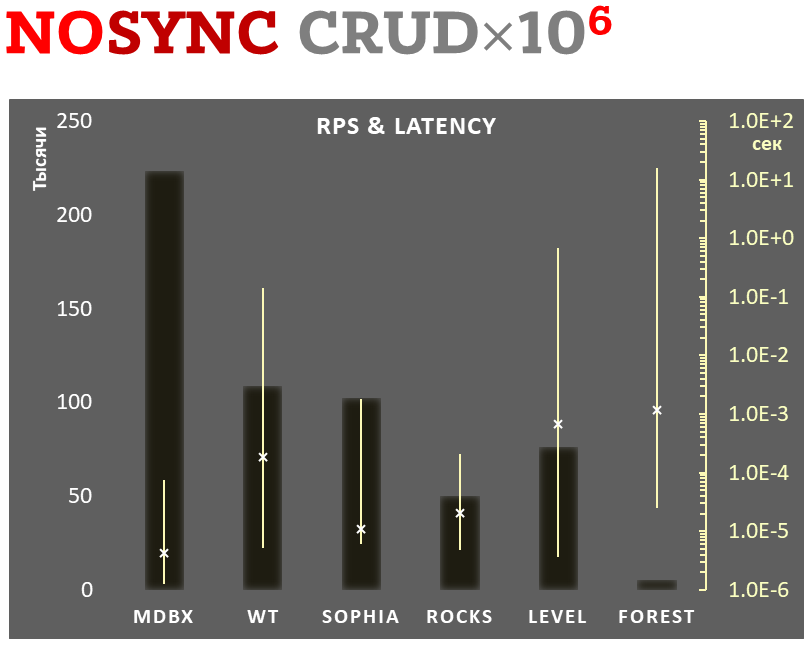
Zároveň mdbx zlepšuje mnohé nedostatky lmdb, takže Erigon (klient novej generácie etherea) nedávno prešiel z LMDB na MDBX [1].
Výukové programy
Ako spustiť príklad
Najprv klonujte kódovú základňu git clone git@github.com:rmw-lib/mdbx.git --depth=1 && cd mdbx
Potom spustite stránku cargo run --example 01 a spustí sa examples/01.rs
Ak ide o váš vlastný projekt, najprv ho spustite:
cargo install cargo-edit
cargo add mdbx lazy_static ctor paste
Príklad 1 : Písanie set(key,val) a čítanie .get(key)
Pozrime sa na jednoduchý príklad/01.rs
Kód
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
Spustite výstup
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/01.mdb
mdbx version https://github.com/erthink/libmdbx/releases/tag/v0.11.2
test1 get Ok(Some(Bin([6])))
[6]
Popis kódu
env_rw! Definovanie databázy
Kód začína makrom env_rw, ktoré má 4 parametre.
Názov premennej prostredia databázy
Vracia objekt, mdbx:: env:: Config.
Použijeme predvolenú konfiguráciu, pretože Env implementuje From<Into<PathBuf>>, takže nám postačí cesta k databáze into() a predvolená konfigurácia je nasledovná.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
max_db Toto nastavenie je možné resetovať pri každom otvorení databázy, ale jeho prílišné nastavenie ovplyvní výkon, nastavte ho len podľa potreby.
Význam ostatných parametrov nájdete v dokumentácii k libmdbx.
Názov makra transakcie čítania databázy, predvolená hodnota je
rNázov makra transakcie zápisu do databázy, predvolená hodnota je
w
Parametre 3 a 4 môžete vynechať, aby sa použili predvolené hodnoty.
Rozšírenie makier
Ak chcete vidieť, čo robí magické makro, môžete na jeho rozbalenie použiť makro cargo expand --example 01, ktoré je potrebné najprv nainštalovať. cargo install cargo-expand
Snímka obrazovky s rozšíreným kódom je uvedená nižšie.

anyhow a lazy_static
Na rozšírenej snímke obrazovky vidíte, že sa používajú adresy lazy_static a anyhow.
anyhow je knižnica na spracovanie chýb pre rust.
lazy_static je statická premenná s odloženou inicializáciou.
Tieto dve knižnice sú veľmi časté a nebudem sa nimi zaoberať.
Makro mdbx!
mdbx! je makro procedúry.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
Prvý riadok je názov premennej prostredia databázy
Druhý riadok je názov databázy
Môže existovať viac ako jedna databáza, jeden riadok pre každú
Vlákna a transakcie
Vyššie uvedený kód demonštruje viacvláknové čítanie a zápis.
Je dôležité si uvedomiť, že v jednom vlákne môže byť v danom čase otvorená len jedna transakcia, ak je vo vlákne otvorených viac transakcií, program sa zrúti.
Transakcia sa vykoná na konci rozsahu.
Čítanie a zápis binárnych údajov
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
set je zápis, get je čítanie a každý objekt, ktorý implementuje AsRef<[u8]> objekt možno zapísať do databázy.
get Vzniká Ok(Some(Bin([6]))), ktorý sa dá premeniť na &[u8].
Príklad 2: Dátové typy, príznaky databázy, mazanie, prechádzanie
Pozrime sa na druhý príklad/02.rs:
V tomto príklade sa vynecháva env_rw! a tretí a štvrtý argument ( r, w).
Kód
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
Spustite výstup
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/02.mdb
u16::from_le_bytes(Bin([4, 5])) = 1284
-- loop test1
[2] = [3]
[2, 3] = [4, 5]
[8, 1] = [9]
[9] = [10, 12]
[97, 98, 99] = [48, 49, 50]
[114, 109, 119, 46, 108, 105, 110, 107] = [68, 111, 119, 110, 32, 119, 105, 116, 104, 32, 68, 97, 116, 97, 32, 72, 101, 103, 101, 109, 111, 110, 121]
[examples/02.rs:57] test1.del_val([8, 1], [3])? = false
[examples/02.rs:58] test1.get([8, 1])?.unwrap() = Bin(
[
9,
],
)
[examples/02.rs:59] test1.del_val([8, 1], [9])? = true
[examples/02.rs:60] test1.get([8, 1])? = None
[examples/02.rs:62] test1.del([9])? = true
[examples/02.rs:63] test1.get([9])? = None
[examples/02.rs:64] test1.del([9])? = false
-- loop test2
abc = 012
rmw.link = Down with Data Hegemony
-- loop test3
0 = 6
10 = 5
13 = 32
16 = 32
-15 = 6
-12 = 6
-10 = 6
[examples/02.rs:100] test4.del_val(0, 2)? = true
[examples/02.rs:101] test4.del_val(0, 2)? = false
-- loop test4 rev
16 = 3
16 = 2
16 = 1
13 = 32
10 = 5
10 = 0
0 = 6
dup(16) 1
dup(16) 2
dup(16) 3
Rýchle čítanie a písanie
Ak chceme jednoducho prečítať alebo zapísať jeden riadok údajov, môžeme použiť syntaktický cukor makra.
Čítanie údajov
r!(Test1.get [2, 3])
Zápis údajov
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Všetko v jednom riadku, ako je napísané v príklade/02.rs.
Typy údajov
V súbore examples/02. rs vyzerá definícia databázy takto :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
kde key a val definujú dátové typy pre kľúče a hodnoty.
Ak sa pokúsite zapísať dátový typ, ktorý nezodpovedá definovanému, zobrazí sa chyba, ako je znázornené na nasledujúcom obrázku :

Predvolený typ údajov je Bin , možno zapísať akékoľvek údaje, ktoré implementujú AsRef<[u8]>.
Ak je kľúčom alebo hodnotou reťazec utf8, dátový typ môže byť nastavený na Str .
Odcitovanie Str vráti reťazec, podobne ako let k:&str = &k;.
Okrem toho Str implementuje aj std::fmt::Display , println!("{}",k) vypíše čitateľný reťazec.
Prednastavené typy údajov
Okrem Str a Bin obsahuje wrapper aj podporu dát usize, u128, u64, u32, u16, u8, isize, i128, i64, i32, i16, i8, f32, f64.
Príznaky databázy
Príznaky databázy pridané k údajom v súbore examples/02.rs si môžete pozrieť na adrese Test4. flag DUPSORT
Databáza libmdbx má niekoľko príznakov ( MDBX_db_flags_t ), ktoré možno nastaviť.
- REVERSEKEY používa pre kľúče reverzné porovnávanie reťazcov. (užitočné pri používaní malých čísel s koncovým kódom ako kľúčov)
- DUPSORT používa zoradené duplikáty, t. j. umožňuje viacero hodnôt pre jeden kľúč.
- INTEGERKEY Natívny číselný kľúč uint32_t alebo uint64_t zoradený v bajtoch. kľúče musia mať rovnakú veľkosť a musia byť zarovnané, keď sa odovzdávajú ako argument.
- DUPFIXED Veľkosť dátových hodnôt musí byť rovnaká, ak sa použije DUPSORT (umožňuje rýchle spočítanie počtu hodnôt).
- Pre INTEGERDUP sa vyžaduje DUPSORT a DUPFIXED; hodnoty sú celé čísla (podobne ako pri INTEGERKEY). Všetky hodnoty údajov musia mať rovnakú veľkosť a musia byť zarovnané, keď sa odovzdávajú ako parametre.
- REVERSEDUP používa DUPSORT; pre hodnoty údajov sa používa reverzné porovnávanie reťazcov.
- CREATE vytvorí DB, ak neexistuje (pridaná v predvolenom nastavení).
- DB_ACCEDE Otvorí existujúcu čiastkovú databázu vytvorenú pomocou príznaku unknown.
Tento príznak DB_ACCEDE je určený na otvorenie existujúcich čiastkových databáz vytvorených s neznámymi príznakmi (REVERSEKEY, DUPSORT, INTEGERKEY, DUPFIXED, INTEGERDUP a REVERSEDUP).
V tomto prípade subdatabáza nevráti chybu INCOMPATIBLE, ale otvorí sa s príznakmi použitými na jej vytvorenie a aplikácia potom môže určiť skutočné príznaky pomocou funkcie mdbx_dbi_flags().
DUPSORT : jednému kľúču zodpovedá viac ako jedna hodnota
DUPSORTznamená, že kľúču môže zodpovedať viac ako jedna hodnota.
Ak chcete nastaviť viacero príznakov, napíšte nasledovne flag DUPSORT | DUPFIXED
.dup(key) iterátor, ktorý vráti všetky hodnoty zodpovedajúce kľúču
Táto funkcia je k dispozícii len pre databázy označené DUPSORT, kde môže kľúču zodpovedať viac ako jedna hodnota.
V prípade databáz DUPSORT vráti get iba prvú hodnotu tohto kľúča. Ak chcete získať všetky hodnoty, použite dup.
Predvolené automaticky pridávané príznaky databázy
Ak je typ údajov u32 / u64 / usize, príznak databázy sa pridá automaticky. INTEGERKEY .
Na počítačoch s malým koncovým kódovaním sa automaticky pridávajú ďalšie číselné typy REVERSEKEY Príznak databázy sa automaticky pridá, ak je typ údajov / / .
Odstránenie údajov
.del(key) Odstránenie kľúča
.del(val) Odstráni hodnotu zodpovedajúcu kľúču.
Ak má databáza príznak DUPSORT, všetky hodnoty pod týmto kľúčom budú vymazané.
Vráti true, ak sú nejaké údaje vymazané, a false, ak nie sú.
.del_val(key,val) Odstránenie presnej zhody
.del_val(key,val) Odstráni dvojice kľúč-hodnota, ktoré presne zodpovedajú vstupným parametrom.
Vráti true, ak sú nejaké údaje vymazané, a false, ak nie sú.
Prechod
sekvenčné prechádzanie
Z dôvodu implementácie std::iter::IntoIterator . môžete prechádzať priamo takto :
for (k, v) in test1
.rev() Prechádzanie v opačnom poradí
for (k, v) in test4.rev()
Triedenie
Kľúče libmdbx sú zoradené v slovníkovom poradí.
Pre čísla bez znamienka
sú zoradené od najmenšieho po najväčší, pretože príznaky databázy sa pridávajú automaticky (
u32/u64/usizesa pridávajú kINTEGERKEY, ostatné sa pridávajú kREVERSEKEYv závislosti od strojového kódu).Pre čísla so znamienkom
poradie je nasledovné: najprv 0, potom všetky kladné čísla od najmenšieho po najväčšie a potom všetky záporné čísla od najmenšieho po najväčšie.
Intervalové iterátory
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
Spustite výstup
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/range.mdb
> Test0
# test0.range([1]..)
(Bin([1]), Bin([1, 2]))
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
(Bin([3]), Bin([]))
# test0.range([1, 1]..=[2])
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
-- all
(2, 4)
(2, 9)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.range(1..3)
(2, 4)
(2, 9)
# test1.range(5..2)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
# test1.range(1..=3)
(2, 4)
(2, 9)
(3, 0)
(3, 8)
# test1.range(..3)
(2, 4)
(2, 9)
# test1.range(3..)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.rev_range(..1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
# test1.rev_range(..=1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
> Test2
# test2.range(1..3)
(1, 5)
(2, 4)
# test2.range(1..=3)
(1, 5)
(2, 4)
# test2.range(..3)
(0, 0)
(1, 5)
(2, 4)
# test2.range(2..)
(2, 4)
(9, 1)
# test2.rev_range(..1)
(9, 1)
(2, 4)
# test2.rev_range(2..)
(2, 4)
(1, 5)
(0, 0)
# test2.rev_range(..=1)
(9, 1)
(2, 4)
(1, 5)
.range(begin..end) Intervalová iterácia
Pre čísla je interval číselný interval.
Pre binárny interval sa dá zostrojiť rovnaký interval, napr.
let begin : &[u8] = &[1,1];
for (k,v) in test0.range(begin..=&[2]) {}
Ak je begin väčšia ako end, bude sa iterovať dozadu.
Napríklad test1.range(5..2) vypíše nasledujúci :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
Intervalová iterácia nie je podporovaná RangeFull , t. j. použitie adresy ..nie je podporované, použite namiesto toho vyššie uvedený spôsob prechádzania.
.rev_range Invertované intervaly
Ak chcete získať prevrátený interval, ktorý je menší alebo rovný určitej hodnote, môžete postupovať takto
test2.rev_range(2..)
Výstupom bude
(2, 4)
(1, 5)
(0, 0)
Pre invertovaný interval nesmie byť nastavená jedna z možností begin alebo end; ak sú totiž nastavené obe, môžete vždy použiť range(end..begin) na dosiahnutie rovnakého efektu.
Prispôsobenie typov údajov
Ukážkový kód je k dispozícii na adrese github.com/rmw-lib/mdbx-example/01
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
Výstup je nasledovný
Some(City { name: "BeiJing", lnglat: (11640, 3990) })
V príklade vlastného typu používame speedy vykonať serializáciu ( speedy performance review ).
Implementácia vlastného typu FromMdbx a ToAsRef sa potom môže uložiť na adrese mdbx.
Ak používate konkrétnu knižnicu na serializáciu, môžete si prispôsobiť aj atribútové makrá, aby ste proces zjednodušili.
Zjednodušenie vlastných typov pomocou atribútových makier
Implementácia atribútového makra je jednoduchá ako mdbx_speedy Kód atribútu makra je nasledujúci :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
Začnite s cargo add mdbx-speedyvo vlastnom projekte a potom si môžete rýchlo prispôsobiť typ (pozri github.com/rmw-lib/mdbx-example/02 pre demonštračný kód).
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
fn main() -> Result<()> {
// Výpis čísla verzie libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Viacvláknové čítanie a zápis
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // Za 1/65536 sekundy
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Názov premennej databázy Env
Test // Test databázy
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Názvy premenných pre databázu ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Rýchly zápis
w!(Test1.set [2, 3],[4, 5]);
// Rýchle čítanie
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Viacnásobné operácie na viacerých databázach v rámci jednej transakcie
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// Transakcia bude viazaná na konci rozsahu
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
use anyhow::Result;
use mdbx::prelude::*;
use mdbx_speedy::MdbxSpeedy;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
Samozrejme, že je stále nepríjemné opakovane písať #[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)], takže môžete použiť derive_alias na ďalšie zjednodušenie kódu.
Poznámka k používaniu
Dĺžka kľúča
- Minimálna veľkosť 0, maximálna ≈ ½ veľkosti stránky (predvolená maximálna veľkosť kľúča 4K je 2022 bajtov), nastavená pri inicializácii databázy
pagesizemôže byť nakonfigurovaná maximálne na65536a musí byť mocninou 2.
Poznámky pod čiarou
Uvádzajú výhody prechodu z LMDB na MDBX.
Spoločnosť Erigon začala s databázovým backendom BoltDB, potom pridala podporu pre BadgerDB a nakoniec úplne prešla na LMDB. v určitom momente sme narazili na problémy so stabilitou, ktoré boli spôsobené používaním LMDB a ktoré tvorcovia nepredpokladali. Odvtedy sme sa pozerali na dobre podporovaný derivát LMDB s názvom MDBX a dúfame, že v budúcnosti využijeme ich zlepšenia stability a prípadne budeme viac spolupracovať. integrácia MDBX je teraz dokončená a je čas na ďalšie testovanie a dokumentáciu.
Výhody prechodu z LMDB na MDBX.
Rast "priestoru (geometrie)" databázových súborov funguje správne. Je to dôležité najmä v systéme Windows. V LMDB je potrebné raz vopred určiť veľkosť pamäťovej mapy (v súčasnosti štandardne používame 2 TB) a ak databázový súbor narastie nad tento limit, proces sa musí reštartovať. V systéme Windows by nastavenie veľkosti mapy pamäte na 2 TB spôsobilo, že súbor databázy by bol na začiatku veľký 2 TB, čo nie je veľmi vhodné. V systéme MDBX sa veľkosť mapy pamäte zväčšuje po 2 Gb. Znamená to občasné premapovanie, ale prináša to lepší používateľský zážitok.
MDBX má prísnejšie kontroly súbežného používania spracovania transakcií a prekrývania transakcií čítania a zápisu v tom istom vlákne vykonávania. To nám umožňuje odhaliť niektoré nezjavné chyby a robí správanie predvídateľnejším.
Za viac ako 5 rokov (odkedy bol MDBX oddelený od LMDB) sa v ňom nahromadilo veľké množstvo bezpečnostných opráv a opráv chýb, ktoré podľa našich vedomostí stále existujú v LMDB. Niektoré z nich sme objavili počas nášho testovania a správcovia MDBX ich vzali vážne a okamžite ich opravili.Pokiaľ ide o databázy, ktoré neustále upravujú údaje, vytvárajú pomerne veľké množstvo regenerovateľného priestoru (v terminológii LMDB známeho aj ako "freelist"). Museli sme opraviť LMDB, aby sme odstránili najzávažnejšie nedostatky v zaobchádzaní s regenerovateľným priestorom (analýza). MDBX venoval osobitnú pozornosť efektívnemu zaobchádzaniu s regenerovateľným priestorom a doteraz ho nebolo potrebné opravovať.
Na základe nášho testovania dosiahol MDBX pri našich pracovných zaťaženiach o niečo lepšie výsledky.
MDBX odhaľuje viac interných telemetrických údajov - viac metrík o tom, čo sa deje v databáze. A tieto údaje máme v aplikácii Grafana - aby sme mohli lepšie rozhodovať o návrhu aplikácie. Napríklad po úplnom prechode na MDBX (odstránenie podpory pre LMDB) zavedieme politiku "commit half full transaction", aby sme zabránili preplneniu/odplneniu diskových kontaktov. To ešte viac zjednoduší náš kód bez vplyvu na výkon.
MDBX podporuje režim "Exclusive open" - používame ho pri migrácii databáz, aby sme zabránili iným čítačkám v prístupe k databáze počas procesu migrácie.