
Le paquet rust pour libmdbx
Le wrapper rust pour la base de données libmdbx.
Annuaire :
Citations
En écrivant 'rmw.link ', j'ai senti que j'avais besoin d'une base de données intégrée.
En raison du débit réseau qu'impliquent l'enregistrement, la lecture et l'écriture fréquents, sqlite3 était trop avancé pour les préoccupations de performance.
Une base de données clé-valeur de niveau inférieur était donc plus appropriée (lmdb est 10 fois plus rapide que sqlite ).

Finalement, j'ai opté pour la version magique de lmdb - mdbx.
Actuellement, le paquetage existant de rust de mdbx-rs (mdbx-sys) de mdbx ne supporte pas Windows, donc j'ai pris sur moi d'empaqueter une version avec le support de Windows.
Prise en charge du stockage des types de rouille personnalisés. Prend en charge les accès multithreads.
La base de données peut être définie dans un module à l'aide de lazy_static, puis simplement introduite et utilisée avec quelque chose comme :
use db::User;
let id = 1234;
let user = r!(User.get id);
Qu'est-ce que libmdbx ?
mdbx est une base de données secondaire basée sur lmdb, par le russe Леонид Юрьев (Leonid Yuriev).
lmdb est une base de données clé-valeur embarquée super rapide.
Le moteur de recherche en texte intégral MeiliSearch est basé sur lmdb.
Le cadre d'apprentissage profond caffe utilise également lmdb comme magasin de données.
mdbx est 30% plus rapide que lmdb dans le test de performance embarqué ioarena.
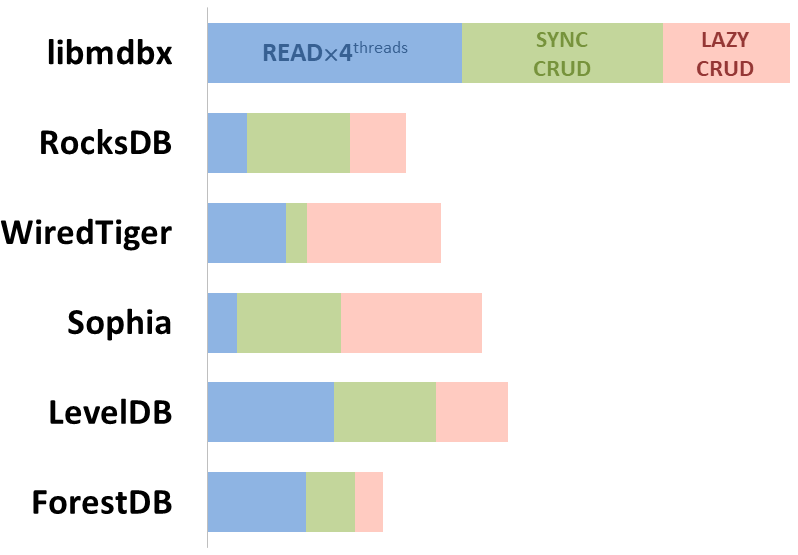
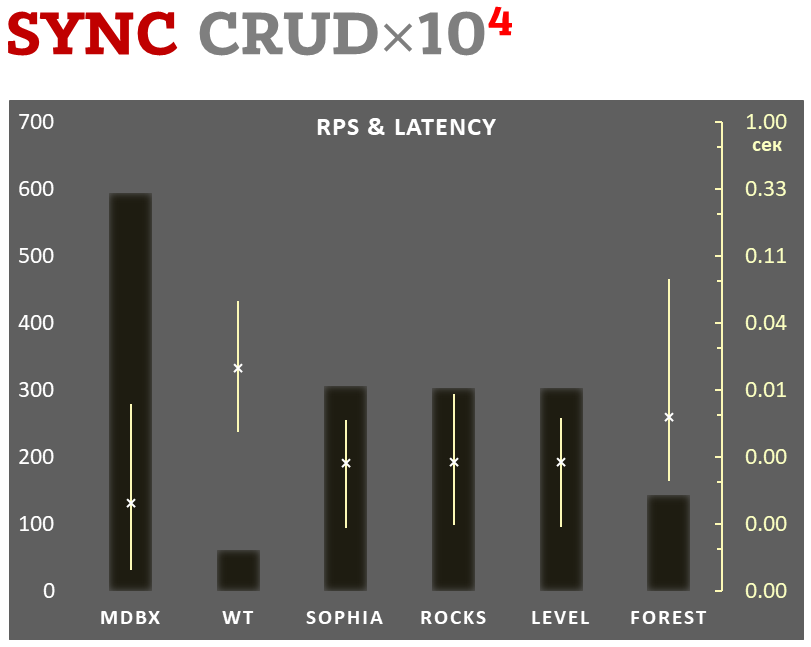
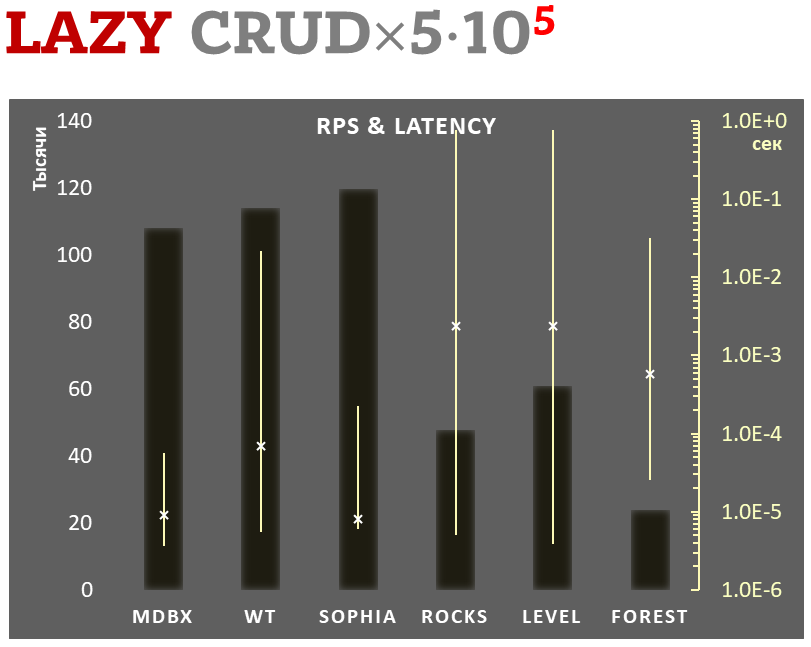
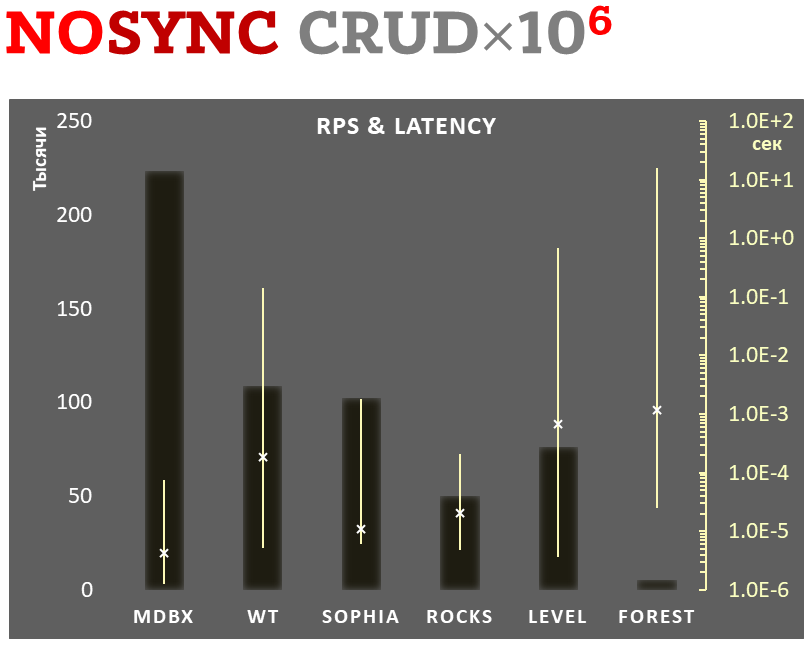
Parallèlement, mdbx améliore de nombreuses lacunes de lmdb. C'est pourquoi Erigon (le client ethereum de nouvelle génération) est récemment passé de LMDB à MDBX [^erigon].
Tutoriels
Comment exécuter l'exemple
Commencez par cloner la base de code git clone git@github.com:rmw-lib/mdbx.git --depth=1 && cd mdbx
Ensuite, exécutez cargo run --example 01 et il s'exécutera examples/01.rs
S'il s'agit de votre propre projet, veuillez l'exécuter d'abord :
cargo install cargo-edit
cargo add mdbx lazy_static ctor paste
Exemple 1 : écrire set(key,val) et lire .get(key)
Prenons un exemple simple, par exemple/01.rs.
Code
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
Exécuter la sortie
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/01.mdb
mdbx version https://github.com/erthink/libmdbx/releases/tag/v0.11.2
test1 get Ok(Some(Bin([6])))
[6]
Description du code
env_rw! Définition de la base de données
Le code commence par une macro env_rw, qui a 4 paramètres.
Le nom de la variable de l'environnement de la base de données
Retourne un objet, mdbx: : env: : Config.
Nous utilisons la configuration par défaut, car Env implémente From<Into<PathBuf>>, donc le chemin de la base de données into() fera l'affaire, et la configuration par défaut est la suivante.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
max_db Ce paramètre peut être réinitialisé à chaque fois que la base de données est ouverte, mais un paramètre trop élevé affectera les performances, il suffit de le définir comme nécessaire.
Voir la documentation de libmdbx pour la signification des autres paramètres.
Le nom de la macro de transaction de lecture de la base de données, la valeur par défaut est
rLe nom de la macro de transaction d'écriture de la base de données, la valeur par défaut est
w
Les paramètres 3 et 4 peuvent être omis pour utiliser les valeurs par défaut.
Macro-expansion
Si vous voulez voir ce que fait la macro magique, vous pouvez utiliser la macro cargo expand --example 01 pour l'étendre, qui doit être installée au préalable. cargo install cargo-expand
Une capture d'écran du code étendu est présentée ci-dessous.

de toute façon et lazy_static
Dans la capture d'écran développée, vous pouvez voir que lazy_static et anyhowsont utilisés.
anyhow est la bibliothèque de gestion des erreurs pour rust.
lazy_static est une variable statique avec une initialisation retardée.
Ces deux bibliothèques sont très courantes et je ne m'y attarderai pas.
La macro mdbx !
mdbx! est une macro de procédure.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
La première ligne est le nom de la variable de l'environnement de la base de données.
La deuxième ligne est le nom de la base de données
Il peut y avoir plus d'une base de données, une ligne pour chaque
Fils et transactions
Le code ci-dessus illustre la lecture et l'écriture multithread.
Il est important de noter qu'il ne peut y avoir qu'une seule transaction dans le même thread à un moment donné. Si un thread a plus d'une transaction ouverte, le programme se bloquera.
La transaction sera engagée à la fin de la portée.
Lecture et écriture de données binaires
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
set est une écriture, get est une lecture, et tout objet qui implémente la fonction AsRef<[u8]> peut être écrit dans la base de données.
get Ce qui en ressort est Ok(Some(Bin([6])))qui peut être converti en &[u8].
Exemple 2 : Types de données, drapeaux de base de données, suppression, traversée.
Regardons le deuxième exemple/02.rs:
Dans cet exemple, env_rw! est omis et les troisième et quatrième arguments ( r, w) sont omis.
Code
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
Exécuter la sortie
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/02.mdb
u16::from_le_bytes(Bin([4, 5])) = 1284
-- loop test1
[2] = [3]
[2, 3] = [4, 5]
[8, 1] = [9]
[9] = [10, 12]
[97, 98, 99] = [48, 49, 50]
[114, 109, 119, 46, 108, 105, 110, 107] = [68, 111, 119, 110, 32, 119, 105, 116, 104, 32, 68, 97, 116, 97, 32, 72, 101, 103, 101, 109, 111, 110, 121]
[examples/02.rs:57] test1.del_val([8, 1], [3])? = false
[examples/02.rs:58] test1.get([8, 1])?.unwrap() = Bin(
[
9,
],
)
[examples/02.rs:59] test1.del_val([8, 1], [9])? = true
[examples/02.rs:60] test1.get([8, 1])? = None
[examples/02.rs:62] test1.del([9])? = true
[examples/02.rs:63] test1.get([9])? = None
[examples/02.rs:64] test1.del([9])? = false
-- loop test2
abc = 012
rmw.link = Down with Data Hegemony
-- loop test3
0 = 6
10 = 5
13 = 32
16 = 32
-15 = 6
-12 = 6
-10 = 6
[examples/02.rs:100] test4.del_val(0, 2)? = true
[examples/02.rs:101] test4.del_val(0, 2)? = false
-- loop test4 rev
16 = 3
16 = 2
16 = 1
13 = 32
10 = 5
10 = 0
0 = 6
dup(16) 1
dup(16) 2
dup(16) 3
Lecture et écriture rapides
Si nous voulons simplement lire ou écrire une seule ligne de données, nous pouvons utiliser le sucre syntaxique d'une macro.
Lire les données
r!(Test1.get [2, 3])
Écriture de données
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Le tout en une seule ligne, comme écrit dans examples/02.rs.
Types de données
Dans exemples/02 .rs, la définition de la base de données ressemble à ceci :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
où key et val définissent les types de données pour les clés et les valeurs respectivement.
Si vous essayez d'écrire un type de données qui ne correspond pas à celui qui a été défini, une erreur sera signalée, comme le montre la capture d'écran ci-dessous :

Le type de données par défaut est Bin Avec le système de gestion des données, il est possible d'écrire sur toutes les données qui mettent en œuvre le site AsRef<[u8]>.
Si la clé ou la valeur est une chaîne de caractères utf8, le type de données peut être défini comme suit Str .
Le fait de déquoter Str renverra une chaîne de caractères, similaire à let k:&str = &k;.
En outre, Str met également en œuvre std::fmt::Displayprintln!("{}",k) produira une chaîne de caractères lisible.
Types de données prédéfinis
En plus de Str et Bin, le wrapper est également livré avec un support de données pour usize, u128, u64, u32, u16, u8, isize, i128, i64, i32, i16, i8, f32, f64.
Drapeaux de base de données
Vous pouvez voir les drapeaux de base de données ajoutés aux données dans examples/02.rs à Test4. flag DUPSORT
La base de données libmdbx possède un certain nombre d'indicateurs ( MDBX_db_flags_t ) qui peuvent être définis.
- REVERSEKEY utilise la comparaison inverse des chaînes pour les clés. (utile lorsque vous utilisez des petits numéros codés en bout de ligne comme clés)
- DUPSORT utilise des doublons triés, c'est-à-dire qu'il autorise plusieurs valeurs pour une clé.
- INTEGERKEY Clé numérique native ordonnée par octets uint32_t ou uint64_t. Les clés doivent avoir la même taille et doivent être alignées lorsqu'elles sont passées comme arguments.
- DUPFIXED La taille des valeurs de données doit être la même si DUPSORT est utilisé (permet un comptage rapide du nombre de valeurs).
- DUPSORT et DUPFIXED sont nécessaires pour INTEGERDUP ; les valeurs sont des entiers (similaires à INTEGERKEY). Les valeurs de données doivent toutes avoir la même taille et doivent être alignées lorsqu'elles sont transmises en tant que paramètres.
- REVERSEDUP utilise DUPSORT ; la comparaison inverse des chaînes de caractères est utilisée pour les valeurs de données.
- CREATE crée la BD si elle n'existe pas (ajoutée par défaut).
- DB_ACCEDE Ouvre une sous-base de données existante créée à l'aide de l'indicateur inconnu.
Cet indicateur DB_ACCEDE est destiné à ouvrir des sous-bases de données existantes créées avec des indicateurs inconnus (REVERSEKEY, DUPSORT, INTEGERKEY, DUPFIXED, INTEGERDUP et REVERSEDUP).
Dans ce cas, la sous-base de données ne renverra pas une erreur INCOMPATIBLE, mais sera ouverte avec les drapeaux utilisés pour la créer, et l'application pourra alors déterminer les drapeaux réels avec mdbx_dbi_flags().
DUPSORT : Une clé correspond à plus d'une valeur
DUPSORTCela signifie qu'une clé peut correspondre à plus d'une valeur.
Si vous voulez définir plusieurs drapeaux, écrivez comme suit flag DUPSORT | DUPFIXED
.dup(key) itérateur qui renvoie toutes les valeurs correspondant à une clé
Cette fonction est uniquement disponible pour les bases de données marquées par DUPSORT où une clé peut correspondre à plus d'une valeur.
Pour les bases de données DUPSORT, get ne renvoie que la première valeur pour cette clé. Pour obtenir toutes les valeurs, utilisez dup.
Drapeaux de base de données ajoutés automatiquement par défaut
Lorsque le type de données est u32 / u64 / usize, l'indicateur de base de données est automatiquement ajouté. INTEGERKEY .
Sur les machines dotées d'un système de codage à petite échelle, d'autres types de chiffres sont automatiquement ajoutés. REVERSEKEY L'indicateur de base de données est automatiquement ajouté lorsque le type de données est / / .
Suppression des données
.del(key) Suppression d'une touche
.del(val) Supprime la valeur correspondant à une clé.
Si la base de données a le drapeau DUPSORT, toutes les valeurs sous cette clé seront supprimées.
Renvoie truesi des données sont supprimées, et falsedans le cas contraire.
.del_val(key,val) Suppression de la correspondance exacte
.del_val(key,val) Supprime les paires clé-valeur qui correspondent exactement aux paramètres d'entrée.
Renvoie truesi des données sont supprimées, et falsedans le cas contraire.
Traversée
traversée séquentielle
En raison de la mise en œuvre de std::iter::IntoIterator . vous pouvez traverser directement comme suit :
for (k, v) in test1
.rev() Traversée de l'ordre inverse
for (k, v) in test4.rev()
Triage
Les clés libmdbx sont triées dans l'ordre du dictionnaire.
Pour les nombres non signés
sont triés du plus petit au plus grand car les drapeaux de la base de données sont automatiquement ajoutés (
u32/u64/usizesont ajoutés àINTEGERKEY, d'autres sont ajoutés àREVERSEKEYselon le code machine).Pour les nombres signés
l'ordre est le suivant : 0 d'abord, puis tous les nombres positifs du plus petit au plus grand, puis tous les nombres négatifs du plus petit au plus grand.
Itérateurs d'intervalles
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
Exécutez la sortie de
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/range.mdb
> Test0
# test0.range([1]..)
(Bin([1]), Bin([1, 2]))
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
(Bin([3]), Bin([]))
# test0.range([1, 1]..=[2])
(Bin([1, 1]), Bin([1, 3]))
(Bin([1, 2]), Bin([1, 3]))
(Bin([2]), Bin([2, 3]))
-- all
(2, 4)
(2, 9)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.range(1..3)
(2, 4)
(2, 9)
# test1.range(5..2)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
# test1.range(1..=3)
(2, 4)
(2, 9)
(3, 0)
(3, 8)
# test1.range(..3)
(2, 4)
(2, 9)
# test1.range(3..)
(3, 0)
(3, 8)
(5, 3)
(5, 8)
(9, 1)
(9, 2)
(9, 7)
# test1.rev_range(..1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
# test1.rev_range(..=1)
(9, 7)
(9, 2)
(9, 1)
(5, 8)
(5, 3)
(3, 8)
(3, 0)
(2, 9)
(2, 4)
> Test2
# test2.range(1..3)
(1, 5)
(2, 4)
# test2.range(1..=3)
(1, 5)
(2, 4)
# test2.range(..3)
(0, 0)
(1, 5)
(2, 4)
# test2.range(2..)
(2, 4)
(9, 1)
# test2.rev_range(..1)
(9, 1)
(2, 4)
# test2.rev_range(2..)
(2, 4)
(1, 5)
(0, 0)
# test2.rev_range(..=1)
(9, 1)
(2, 4)
(1, 5)
.range(begin..end) Intervalle Iteration
Pour les nombres, un intervalle est un intervalle numérique.
Pour le binaire, le même intervalle peut être construit, par exemple
let begin : &[u8] = &[1,1];
for (k,v) in test0.range(begin..=&[2]) {}
Si begin est supérieur à end, l'itération se fera en sens inverse.
Par exemple, test1.range(5..2) produira le résultat suivant :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
L'itération par intervalles n'est pas prise en charge RangeFull L'utilisation de ..n'est pas supportée, veuillez utiliser la traversée mentionnée ci-dessus à la place.
.rev_range Intervalles inversés
Si vous voulez obtenir un intervalle inversé qui est inférieur ou égal à une valeur, vous pouvez procéder comme suit
test2.rev_range(2..)
La sortie sera
(2, 4)
(1, 5)
(0, 0)
L'une des deux options begin ou end ne doit pas être définie pour l'intervalle inversé, car si les deux sont définies, vous pouvez toujours utiliser range(end..begin) pour obtenir le même effet.
Personnalisation des types de données
Le code de démonstration est disponible à l'adresse github.com/rmw-lib/mdbx-example/01.
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
Le résultat est le suivant
Some(City { name: "BeiJing", lnglat: (11640, 3990) })
Dans l'exemple du type personnalisé, nous utilisons speedy pour faire la sérialisation ( speedy examen des performances ).
Mise en œuvre de types personnalisés FromMdbx et ToAsRef peut alors être stocké sur mdbx.
Si vous utilisez une bibliothèque de sérialisation spécifique, vous pouvez également personnaliser les macros d' attributs pour simplifier le processus.
Simplifier les types personnalisés avec les macros d'attributs
La mise en œuvre d'une macro d'attribut est aussi simple que mdbx_speedy Le code de la macro attributaire est le suivant :
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
Commencez par cargo add mdbx-speedydans votre propre projet, puis vous pourrez rapidement personnaliser le type (voir github.com/rmw-lib/mdbx-example/02 pour le code de démonstration).
use db::User;
let id = 1234;
let user = r!(User.get id);
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(
MDBX,
{
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
},
r,
w
);
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
fn main() -> Result<()> {
// Afficher le numéro de version de libmdbx
unsafe {
println!(
"mdbx version https://github.com/erthink/libmdbx/releases/tag/v{}.{}.{}",
mdbx_version.major, mdbx_version.minor, mdbx_version.release
);
}
// Lecture et écriture multithreads
let t = std::thread::spawn(|| {
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t: &[u8] = &val;
println!("{:?}", t);
}
None => unreachable!(),
}
Ok(())
});
t.join().unwrap()?;
Ok(())
}
#[derive(Clone, Debug)]
pub struct Config {
path: PathBuf,
mode: ffi::mdbx_mode_t,
flag: flag::ENV,
sync_period: u64,
sync_bytes: u64,
max_db: u64,
pagesize: isize,
}
lazy_static! {
pub static ref ENV_CONFIG_DEFAULT: Config = Config {
path:PathBuf::new(),
mode: 0o600,
//https://github.com/erthink/libmdbx/issues/248
sync_period : 65536, // En 1/65536e de seconde
sync_bytes : 65536,
max_db : 256,
flag : (
flag::ENV::MDBX_EXCLUSIVE
| flag::ENV::MDBX_LIFORECLAIM
| flag::ENV::MDBX_COALESCE
| flag::ENV::MDBX_NOMEMINIT
| flag::ENV::MDBX_NOSUBDIR
| flag::ENV::MDBX_SAFE_NOSYNC
// | flag::ENV::MDBX_SYNC_DURABLE
),
pagesize:-1
};
}
mdbx! {
MDBX // Nom de la variable de la base de données Env
Test // Test de la base de données
}
let tx = w!();
let test = tx | Test;
test.set([1, 2], [6])?;
println!("test1 get {:?}", test.get([1, 2]));
match test.get([1, 2])? {
Some(val) => {
let t:&[u8] = &val;
println!("{:?}",t);
},
None => unreachable!()
}
use anyhow::{Ok, Result};
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX // Noms de variables pour la base de données ENV
Test1
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
}
fn main() -> Result<()> {
// Écriture rapide
w!(Test1.set [2, 3],[4, 5]);
// Lecture rapide
match r!(Test1.get [2, 3]) {
Some(r) => {
println!(
"\nu16::from_le_bytes({:?}) = {}",
r,
u16::from_le_bytes((*r).try_into()?)
);
}
None => unreachable!(),
}
// Opérations multiples sur plusieurs bases de données dans la même transaction
{
let tx = w!();
let test1 = tx | Test1;
test1.set(&[9], &[10, 12])?;
test1.set([8, 1], [9])?;
test1.set("rmw.link", "Down with Data Hegemony")?;
test1.set(&"abc", &"012")?;
println!("\n-- loop test1");
for (k, v) in test1 {
println!("{} = {}", k, v);
}
dbg!(test1.del_val([8, 1], [3])?);
dbg!(test1.get([8, 1])?.unwrap());
dbg!(test1.del_val([8, 1], [9])?);
dbg!(test1.get([8, 1])?);
dbg!(test1.del([9])?);
dbg!(test1.get([9])?);
dbg!(test1.del([9])?);
let test2 = tx | Test2;
test2.set("rmw.link", "Down with Data Hegemony")?;
test2.set(&"abc", &"012")?;
println!("\n-- loop test2");
for (k, v) in test2 {
println!("{} = {}", k, v);
}
let test3 = tx | Test3;
test3.set(13, 32)?;
test3.set(16, 32)?;
test3.set(-15, 6)?;
test3.set(-10, 6)?;
test3.set(-12, 6)?;
test3.set(0, 6)?;
test3.set(10, 5)?;
println!("\n-- loop test3");
for (k, v) in test3 {
println!("{:?} = {:?}", k, v);
}
let test4 = tx | Test4;
test4.set(10, 5)?;
test4.set(10, 0)?;
test4.set(13, 32)?;
test4.set(16, 2)?;
test4.set(16, 1)?;
test4.set(16, 3)?;
test4.set(0, 6)?;
test4.set(10, 5)?;
test4.set(0, 2)?;
dbg!(test4.del_val(0, 2)?);
dbg!(test4.del_val(0, 2)?);
println!("\n-- loop test4 rev");
for (k, v) in test4.rev() {
println!("{:?} = {:?}", k, v);
}
for i in test4.dup(16) {
println!("dup(16) {:?}", i);
}
// La transaction sera engagée à la fin de la portée.
}
Ok(())
}
w!(Test1.set [2, 3],[4, 5])
Test2
key Str
val Str
Test3
key i32
val u64
Test4
key u64
val u16
flag DUPSORT
use anyhow::Result;
use mdbx::prelude::*;
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
println!("mdbx file path {}", db_path.display());
db_path.into()
});
mdbx! {
MDBX
Test0
Test1
key u16
val u64
flag DUPSORT
Test2
key u32
val u64
}
macro_rules! range_rev {
($var:ident, $range:expr) => {
println!("\n# {}.rev_range({:?})", stringify!($var), $range);
for i in $var.range_rev($range) {
println!("{:?}", i);
}
};
}
macro_rules! range {
($var:ident, $range:expr) => {
println!("\n# {}.range({:?})", stringify!($var), $range);
for i in $var.range($range) {
println!("{:?}", i);
}
};
}
fn main() -> Result<()> {
{
println!("\n> Test0");
let tx = &MDBX.w()?;
let test0 = tx | Test0;
test0.set([0], [0, 1])?;
test0.set([1], [1, 2])?;
test0.set([2], [2, 3])?;
test0.set([1, 1], [1, 3])?;
test0.set([1, 2], [1, 3])?;
test0.set([3], [])?;
range!(test0, [1]..);
let begin: &[u8] = &[1, 1];
range!(test0, begin..=&[2]);
}
{
let tx = &MDBX.w()?;
let test1 = tx | Test1;
test1.set(2, 9)?;
test1.set(2, 4)?;
test1.set(9, 7)?;
test1.set(3, 0)?;
test1.set(3, 8)?;
test1.set(5, 3)?;
test1.set(5, 8)?;
test1.set(9, 1)?;
println!("-- all");
for i in test1 {
println!("{:?}", i);
}
range!(test1, 1..3);
range!(test1, 5..2);
range!(test1, 1..=3);
range!(test1, ..3);
range!(test1, 3..);
range_rev!(test1, ..1);
range_rev!(test1, ..=1);
}
{
println!("\n> Test2");
let tx = &MDBX.w()?;
let test2 = tx | Test2;
test2.set(2, 9)?;
test2.set(1, 2)?;
test2.set(2, 4)?;
test2.set(1, 5)?;
test2.set(9, 7)?;
test2.set(9, 1)?;
test2.set(0, 0)?;
range!(test2, 1..3);
range!(test2, 1..=3);
range!(test2, ..3);
range!(test2, 2..);
range_rev!(test2, ..1);
range_rev!(test2, 2..);
range_rev!(test2, ..=1);
}
Ok(())
}
(5, 8)
(5, 3)
(3, 8)
(3, 0)
use anyhow::Result;
use mdbx::prelude::*;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
impl FromMdbx for City {
fn from_mdbx(_: PtrTx, val: MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl ToAsRef<City, Vec<u8>> for City {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
env_rw!(MDBX, {
let mut db_path = std::env::current_exe().unwrap();
db_path.set_extension("mdb");
db_path.into()
});
mdbx! {
MDBX
Test
key u16
val City
}
fn main() -> Result<()> {
let city = City {
name: "BeiJing".into(),
lnglat: (11640, 3990),
};
let tx = w!();
let test = tx | Test;
test.set(1, city)?;
println!("{:?}", test.get(1)?);
Ok(())
}
extern crate proc_macro;
extern crate syn;
#[macro_use]
extern crate quote;
use proc_macro::TokenStream;
#[proc_macro_derive(MdbxSpeedy)]
pub fn mdbx_speedy(ts: TokenStream) -> TokenStream {
let ast: syn::DeriveInput = syn::parse(ts).unwrap();
let name = &ast.ident;
quote! {
impl mdbx::prelude::FromMdbx for #name {
fn from_mdbx(_: mdbx::prelude::PtrTx, val: mdbx::prelude::MDBX_val) -> Self {
Self::read_from_buffer(val_bytes!(val)).unwrap()
}
}
impl mdbx::prelude::ToAsRef<#name, Vec<u8>> for #name {
fn to_as_ref(&self) -> Vec<u8> {
self.write_to_vec().unwrap()
}
}
}
.into()
}
use anyhow::Result;
use mdbx::prelude::*;
use mdbx_speedy::MdbxSpeedy;
use speedy::{Readable, Writable};
#[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)]
pub struct City {
name: String,
lnglat: (u32, u32),
}
Bien sûr, il est toujours ennuyeux d'écrire #[derive(PartialEq, Debug, Readable, Writable, MdbxSpeedy)] de manière répétée, donc vous pouvez utiliser derive_alias pour simplifier davantage le code.
Note sur l'utilisation de
La longueur de la clé
- Minimum 0, maximum ≈ ½ taille de page (par défaut 4K page clé taille maximale est 2022 octets), défini lors de l'initialisation de la base de données
pagesizepeut être configuré à pas plus de65536et doit être une puissance de 2.
Notes de bas de page
[^erigon] : Erigon (le client Ethernet de nouvelle génération) est récemment passé de LMDB à MDBX.
Ils citent les avantages de la transition de LMDB à MDBX.
Erigon a commencé avec une base de données BoltDB, puis a ajouté la prise en charge de BadgerDB et a finalement migré complètement vers LMDB. À un moment donné, nous avons rencontré des problèmes de stabilité causés par notre utilisation de LMDB qui n'avaient pas été prévus par les créateurs. Depuis lors, nous avons étudié un dérivé de LMDB bien supporté, appelé MDBX, et nous espérons profiter de ses améliorations en matière de stabilité et éventuellement collaborer davantage à l'avenir. L'intégration de MDBX est maintenant terminée et il est temps de procéder à d'autres tests et à la documentation.
Avantages de la transition de LMDB à MDBX.
La croissance "espace (géométrie)" des fichiers de la base de données fonctionne correctement. C'est important, surtout sous Windows. Dans LMDB, il faut spécifier la taille de la carte mémoire une fois à l'avance (actuellement, nous utilisons 2 To par défaut) et si le fichier de la base de données dépasse cette limite, le processus doit être redémarré. Sous Windows, si la taille de la carte mémoire est fixée à 2 To, le fichier de la base de données aura une taille initiale de 2 To, ce qui n'est pas très pratique. Dans MDBX, la taille de la carte mémoire est augmentée par incréments de 2 Go. Cela implique un remappage occasionnel, mais se traduit par une meilleure expérience utilisateur.
MDBX effectue des contrôles plus stricts sur l'utilisation simultanée du traitement des transactions et le chevauchement des transactions de lecture et d'écriture dans le même fil d'exécution. Cela nous permet de repérer certaines erreurs non évidentes et rend le comportement plus prévisible.
En plus de 5 ans (depuis qu'il a été séparé de LMDB), MDBX a accumulé un grand nombre de correctifs de sécurité et d'heisenbugs qui, à notre connaissance, existent toujours dans LMDB. Certains d'entre eux ont été découverts lors de nos tests, et les responsables de MDBX les ont pris au sérieux et les ont corrigés rapidement.Les bases de données qui modifient constamment leurs données créent une grande quantité d'espace récupérable (également appelé "freelist" dans la terminologie LMDB). Nous avons dû patcher LMDB pour corriger les défauts les plus graves dans la gestion de l'espace récupérable ( analyse). MDBX a accordé une attention particulière à la gestion efficace de l'espace récupérable et, jusqu'à présent, n'a pas eu besoin d'être patché.
D'après nos tests, MDBX a obtenu des résultats légèrement meilleurs sur nos charges de travail.
MDBX expose davantage de données de télémétrie interne, c'est-à-dire davantage de mesures sur ce qui se passe dans la base de données. Et nous avons ces données dans Grafana - pour prendre de meilleures décisions sur la conception des applications. Par exemple, après la transition complète vers MDBX (suppression de la prise en charge de LMDB), nous mettrons en œuvre une politique de "commit half full transaction" pour éviter les contacts de disque en surnombre ou non. Cela simplifiera davantage notre code sans affecter les performances.
MDBX supporte le mode "Ouverture exclusive" - nous l'utilisons pour les migrations de bases de données afin d'empêcher tout autre lecteur d'accéder à la base de données pendant le processus de migration.